IT Incident Management Fully Examined: Step-By-Step Process, Best Practices & How AI Is Being Used
 By Ron Avignone
By Ron Avignone
Something is wrong. An application is down, users cannot log in, and your inbox is filling up with complaints. What happens next, and how fast, depends entirely on whether your organization has a solid IT incident management process in place.
IT incidents are unavoidable. Every organization that relies on technology will experience service disruptions. Research consistently shows that even a single hour of unplanned downtime can cost large enterprises $100,000 or more. For revenue-generating services, that number can climb significantly higher. The question is not whether incidents will happen, but how well you are prepared to handle them when they do.
This guide covers everything you need to know about IT incident management: what it is, how the process works, the key roles involved, how to measure success, and what best practices actually make a difference.
If you are building an incident management process from scratch or looking to improve what you already have, you will find practical guidance here.

What Is IT Incident Management?
IT incident management is the structured process IT teams use to detect, respond to, and resolve unplanned service disruptions, such as system outages, security breaches, or performance degradations, and restore normal operations as quickly as possible, minimizing business impact. It is a key IT Service Management (ITSM) function guided by ITIL frameworks, with a focus on speed, clear communication, and service continuity.
An incident is any unplanned event that interrupts or degrades an IT service. That might include:
- A server going offline
- An application crashing
- A network slowdown
- A failed software deployment
- A cloud service outage
- A security alert that impacts availability
The goal of incident management is not just to fix the problem. It is to do it fast, communicate clearly along the way, and capture enough information to prevent the same issue from happening again.
It is worth noting what incident management is not. It is not the same as problem management (which finds root causes), change management (which handles planned modifications to IT systems), or service request management (which handles planned asks like password resets or access requests). An incident is always unplanned. Those are related processes, but they serve different purposes. More on that in the next sections.
For a broader look at how incident management fits into your overall IT operations, Giva's guide to ITSM best practices is a helpful starting point.
Benefits of IT Incident Management
A well-run incident management process delivers measurable value across the organization:
- Reduces downtime and restores normal service operations faster
- Maintains employee productivity and customer satisfaction during and after disruptions
- Creates a feedback loop for identifying root causes and preventing future incidents
- Improves SLA compliance by giving teams a consistent, repeatable response framework
IT Incident Management vs. Problem Management vs. Change Management
These three terms get mixed up constantly. They are all part of ITSM, but they work at different stages of the IT service lifecycle.
Here is a quick breakdown:
- Incident Management → Reactive: Focuses on restoring service as quickly as possible after something goes wrong. The goal is speed and minimal business impact. It does not focus on finding the root cause.
- Problem Management → Investigative: Looks at the root cause behind one or more incidents. Root cause analysis is how you move from fixing symptoms to preventing recurrence. Problem management works to eliminate recurring incidents by addressing what is actually causing them.
- Change Management → Proactive and Planned: Manages the process of implementing changes to IT systems, infrastructure, or services. Changes are often introduced to fix problems, but they go through a structured approval process to avoid introducing new incidents.
A simple way to think about it: you use incident management to put out the fire, problem management to figure out why the fire started, and change management to make sure the building is safer going forward.
In ITIL 4, incident management and problem management are considered separate practices, but they work closely together. An incident record can trigger a problem record. A problem resolution often drives a change management process. These processes hand off to each other throughout the service lifecycle.
How Incident, Problem, and Change Management Compare
Incident Management |
Problem Management |
Change Management |
|
Purpose |
Restore service as quickly as possible |
Find and eliminate the root cause of incidents |
Manage planned modifications to IT systems safely |
Approach |
Reactive |
Investigative |
Proactive and planned |
Primary goal |
Minimize downtime and business impact |
Prevent recurring incidents |
Reduce the risk of new incidents from changes |
Triggered by |
An unplanned service disruption |
Recurring incidents or a post-incident review |
A problem resolution, planned improvement, or new requirement |
Output |
Restored service and a closed incident ticket |
Root cause identified; workaround or permanent fix |
Approved, implemented, and reviewed change |
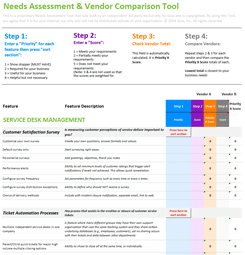
The IT Incident Management Process, Step by Step Workflow
Most incident management processes follow a similar lifecycle, whether you are running a traditional ITIL shop or a modern DevOps team. Here are the key steps:
-
Step 1: Incident Detection and Identification
Incidents are detected in one of two ways:
- Monitoring tools spot an anomaly automatically
- A user reports something is wrong.
Automated monitoring is faster and catches issues before users notice them, which is why investing in good monitoring tools matters.
In ITIL environments, this ties closely to event management, which is the practice of monitoring IT infrastructure for events that may indicate a potential or actual incident, and then routing relevant ones into the incident management process.
-
Step 2: Incident Logging and Recording
Every incident needs a record, typically logged as a ticket in your ITSM or ticketing system. That record should capture:
- Date and time reported
- Who reported it
- The system or service affected
- An initial description of the issue
Good logging is not just for compliance. It is what lets you track trends and measure performance over time.
-
Step 3: Classification and Categorization
Once an incident is logged, it needs to be categorized. Incident classification, or sorting incidents by type (hardware, software, network, and so on), helps route the incident to the right team and makes it easier to analyze patterns later. Consistent categorization is one of the most overlooked parts of a solid incident management process.
-
Step 4: Prioritization
Not all incidents are equal. Prioritization is based on two factors: urgency (how quickly does this need to be fixed?) and impact (how many users or business functions are affected?)
Many teams formalize this with a priority matrix, which is a simple grid that maps combinations of urgency and impact to a defined priority level--typically expressed as low, medium, or high priority. This removes guesswork and keeps the team consistent when multiple incidents are competing for attention.
Note that priority (the order in which incidents are addressed) is related to but distinct from severity (the extent of service impact). This is where severity levels come in, but more on those in the next section.
-
Step 5: Initial Diagnosis and Escalation
The first-level support team attempts to diagnose and resolve the incident. If they cannot fix it within the agreed timeframe, the incident is escalated to a more specialized team.
During diagnosis, teams often consult the CMDB (Configuration Management Database), which is a central record of IT assets, their configurations, and their dependencies. Knowing which configuration items are linked to the affected service can significantly speed up root cause identification.
There are two main types of escalation worth knowing. Functional escalation routes the incident to the team with the right technical knowledge for the problem, regardless of seniority. Hierarchical escalation moves it up the management chain when the severity or business impact requires higher-level authority.
Many organizations also use automatic escalation rules that trigger if a responder does not acknowledge an alert within a set timeframe. Our guide to incident escalation goes deeper on how to structure your escalation policies.
-
Step 6: Resolution and Recovery
The assigned team works to resolve the incident and restore normal service. The fix might be a workaround (a temporary solution to restore service quickly) or a permanent fix. Our incident resolution guide covers what a strong resolution process looks like in practice. Both types of fix are valid at this stage. The priority is getting the service back up.
-
Step 7: Incident Closure
Once the issue is resolved and the user confirms the service is working, the incident is formally closed. The record should be updated with the resolution details, the time to resolve, and any relevant notes. Do not skip this step. A clean closure record is valuable data.
-
Step 8: Post-Incident Review
For significant incidents, especially major ones, a post-incident review (also called a postmortem) is critical. This is a structured review of what happened, what the team did, what worked, and what should change. The goal is to learn and improve, not to find fault.
ITIL vs. DevOps/SRE Approaches to Incident Management
There are two broad schools of thought when it comes to incident management, and most organizations fall somewhere in between:
- The ITIL approach is structured and process-driven. It emphasizes documentation, defined roles, formal escalation paths, and service level agreements. It works well in larger, more traditional IT environments where stability and compliance matter most.
- The DevOps/SRE approach prioritizes speed and shared ownership. Development and operations teams are jointly responsible for the services they build. Engineers carry on-call responsibilities, incidents are resolved quickly, and postmortems are blameless and forward-looking.
Neither approach is universally better. Many organizations blend elements of both, using ITIL-style structure for formal record-keeping and SLA tracking, while adopting DevOps practices like on-call rotations and blameless reviews for faster response.
What Is Major Incident Management?
Major incidents, typically SEV 1, demand a distinct operational model.
Unlike routine incidents, major incidents often:
- Affect revenue-generating systems
- Impact large user populations
- Carry regulatory or reputational risk
Mature organizations activate a Major Incident Management (MIM) process that includes:
- A designated Incident Manager or Incident Commander
- A centralized communication bridge or war room
- Clearly defined responder roles
- Executive stakeholder updates
- Formal communication templates
- Dedicated postmortem documentation
The Incident Commander's role is particularly critical during a major incident. They coordinate responders, manage priorities, and prevent side conversations from derailing resolution efforts.
For example, if a cloud-based customer portal becomes unreachable during peak business hours, the MIM process ensures:
- Monitoring tools trigger alerts immediately
- On-call engineers are paged
- Leadership receives structured updates
- Communication to customers is coordinated
- Technical teams remain focused on restoration
Without this predefined structure, teams often lose critical time debating next steps during the most important window.
For a more in-depth look, see our article on Major Incident Management.
Incident Severity Levels Explained
Severity levels give your team a shared language for how serious an incident is. Without them, you end up wasting critical early minutes debating whether something is urgent or not.
Most organizations use three to five severity levels. Here is a common model:
-
SEV 1 (Critical):
A service is completely down or a major security breach is active. All hands on deck. This requires immediate response and executive visibility.
Example: Your customer-facing application is unreachable for all users.
-
SEV 2 (Major):
A significant function is broken or a large subset of users is affected. Urgent response required, but not a full crisis.
Example: A specific module in your ERP system is throwing errors for one department.
-
SEV 3 (Minor):
A low-impact issue that causes inconvenience but does not significantly disrupt operations. Can be handled during normal business hours.
Example: A report is generating with incorrect formatting.
- SEV 4 (Low):
Minor inconvenience with minimal business effect.
Severity levels matter because they drive everything downstream, with who gets paged, what the SLA targets are, and how quickly escalation happens. Your severity definitions should be documented and shared with the whole team so everyone uses them consistently.
Key Roles in IT Incident Management
Good incident management is a team effort, but everyone needs to know their role. Here are the core positions involved.
-
Incident Manager
Oversees the incident management process. Ensures the right people are involved, communication is flowing, and resolution is moving forward. For major incidents, this person often leads the bridge call or war room.
-
Incident Commander
Common in DevOps and SRE environments, the Incident Commander (sometimes called IC) takes operational control during an active incident. They coordinate the response, make prioritization calls, and keep the team focused, similar to the Incident Manager role in ITIL, but typically with a more hands-on, real-time focus during the incident itself.
-
Service Desk Analyst (Tier 1)
The first point of contact. Logs the incident, handles initial diagnosis, and resolves straightforward issues. Escalates anything beyond their scope. For more on what Tier 1 IT support handles day to day, see our dedicated guide.
-
Tier 2 Support Specialists
Handle more complex issues that require specialized knowledge or deeper system access. Often organized by technology area (network, database, application, etc.). See also: Tier 2 IT support.
-
Tier 3 / Subject Matter Experts
The deepest level of technical expertise. May include internal architects, senior engineers, or external vendors. Brought in for the most complex or critical incidents. See also: Tier 3 IT support.
-
Major Incident Team
A cross-functional group activated for SEV 1 or high-impact incidents. Includes senior technical staff, the Incident Manager, and often communications and leadership stakeholders.
-
Problem Manager
Works alongside incident management but focuses on root cause analysis after incidents are resolved.
In smaller organizations, one person may fill several of these roles. What matters is that the responsibilities are clearly assigned, even if one person is wearing multiple hats.
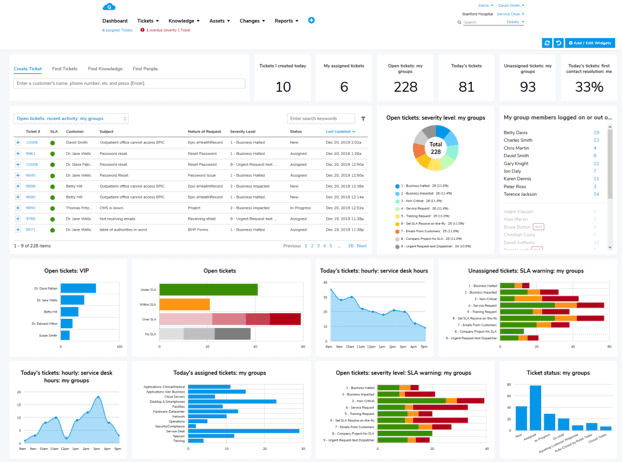
IT Incident Management KPIs and Metrics
If you cannot measure your incident management process, you cannot improve it. These are the most important metrics to track:
-
Mean Time to Detect (MTTD)
How long it takes from when an incident occurs to when it is detected. Lower is better. Good monitoring tools directly improve this metric.
-
Mean Time to Acknowledge (MTTA)
How long it takes from when an alert fires to when a responder officially acknowledges it. MTTA sits between MTTD and MTTR in the incident timeline.
A high MTTA often points to gaps in on-call coverage, alert fatigue causing people to ignore notifications, or unclear system ownership. Getting MTTA down means someone is actively engaged faster before a problem has time to compound into a larger outage.
-
Mean Time to Resolve (MTTR)
How long it takes from detection to full resolution. This is the most commonly cited incident management metric. Industry benchmarks vary, but keeping standard incidents under four hours is a reasonable target for most IT teams. For a deeper look at this metric, see our guide on time to resolution.
-
First Contact Resolution (FCR)
The percentage of incidents resolved at Tier 1 without escalation. High FCR means your service desk is well-trained and your knowledge base is effective. Read more about First Contact Resolution and how to improve it.
-
SLA Compliance Rate
How often incidents are resolved within the agreed service level agreement timeframes, broken out by priority or severity level. An SLA breach can carry real consequences, from financial penalties to damaged client relationships. Tracking this metric consistently is the best way to catch problems before they reach that point.
-
Incident Volume
Total number of incidents over a given period. Trending upward? Something in the environment is getting worse. Trending down after a change? That change probably helped.
-
Backlog Count
The number of open incidents at any point in time. A growing backlog signals a capacity problem or a triage process that is not working.
-
Percentage of Major Incidents
What portion of your total incidents are classified as high-severity. If this number is rising, your infrastructure or change management process may need attention.
-
Customer Satisfaction (CSAT)
Post-incident surveys that measure how users felt about the support they received. You can have fast resolution times and still score poorly if communication was poor.
Understanding SLAs, KPIs, SLOs, and SLIs
SLAs (Service Level Agreements) define the commitments your IT team makes, either to customers or to internal business units. They spell out response times, resolution times, and availability targets.
KPIs (Key Performance Indicators) measure how well your team is actually performing against its goals. They are internal tracking tools.
The two work together. Your SLA might say that SEV 1 incidents must be resolved within four hours. Your MTTR KPI tells you whether you are actually hitting that target, and by how much. Tracking KPIs helps you spot problems before they turn into SLA violations.
In more mature or SRE-aligned environments, you may also work with SLOs (Service Level Objectives) and SLIs (Service Level Indicators). An SLI is the actual metric you measure, including uptime percentage, error rate, or response time. An SLO is the internal target you set for that SLI. An SLA is the formal commitment that specifies what happens if you miss it. The three work in sequence: SLI measures it, SLO targets it, SLA commits to it.
SLOs also play a direct role in incident management. When a service is tracking toward missing its SLO, such as availability dropping below a 99.9% target, that is often the signal to escalate or investigate proactively, before a full outage occurs. Many SRE teams track an error budget alongside each SLO: the amount of downtime or errors still permitted before the objective is breached. A shrinking error budget is an early warning that incident response posture needs to tighten.
For more information, see our article: SLI, SLO & SLA: What's the Difference?
IT Incident Management Best Practices
Here is what separates teams that manage incidents well from those that are constantly putting out fires:
-
Document Your Incident Response Plan
Before an incident happens is the time to decide how you will handle one. An incident response plan documents:
- Your escalation paths
- Severity definitions
- Communication procedures
- Key contacts
When something goes wrong at 2am, your team should be executing a plan, not writing one.
-
Build and Maintain Runbooks
A runbook is a documented set of steps for handling a specific incident type. Think of it as a playbook your team can reach for when they do not have time to think from scratch. A good runbook covers:
- What symptoms to look for
- The first diagnostic steps to take
- When and how to escalate
- The resolution steps
Build runbooks for your most common incident types and review them after every major incident they are used in.
-
Standardize Your Incident Logging
Every incident should be recorded the same way. Consistent fields, consistent categories, consistent severity definitions. Inconsistent data makes it impossible to spot trends or measure improvement.
-
Build and Maintain a Knowledge Base
Document resolutions, workarounds, and known errors. When the same issue comes up again, and it will, your team should not have to start from scratch. A good knowledge base also enables user self-service for common issues.
-
Define Escalation Paths Clearly
Who does Tier 1 contact when they cannot resolve an issue? Who is the on-call engineer for each system? Escalation paths should be documented, visible, and regularly reviewed. If your team has to figure out who to call during a major incident, you have already lost time.
-
Automate Where It Makes Sense
Low-risk, repetitive incidents, such as password resets, disk space alerts, and routine restarts, are ideal candidates for IT process automation. Automation reduces manual workload and speeds resolution for common issues, freeing your team to focus on more complex problems.
-
Use Monitoring Tools Proactively
Do not wait for users to report problems. Set up automated monitoring and alerting so your team knows about issues before users do. Early detection is one of the most effective ways to reduce MTTR.
-
Conduct Blameless Postmortems for Major Incidents
After every significant incident, run a structured review focused on what happened and what can improve, not on who made a mistake. Blameless postmortems build a culture of learning and continuous improvement.
-
Review Metrics Regularly
Set a cadence for reviewing your incident KPIs, like weekly for operational metrics, monthly for trend analysis. Look for patterns: recurring incident types, systems that generate more than their share of tickets, or times of day when incidents spike.
-
Communicate Proactively and Have Guidelines for How to Do It
Do not wait for users to ask for updates. Define in advance what updates go out, at what intervals, through what channels, and who is responsible for sending them. Having communication guidelines written down means your team is not making those decisions under pressure during an active incident.
-
Tie Severity Levels to SLA Targets
Your response and resolution time commitments should align directly with your severity definitions. SEV 1 incidents should have tighter SLA windows than SEV 3 incidents. This alignment keeps expectations consistent across the team and with users.
How AI and Automation Are Changing IT Incident Management
AI is having a real impact on incident management, and not just in marketing materials:
-
Faster Detection
AI-powered monitoring tools can detect anomalies in real time, often before users notice anything is wrong. They analyze patterns across logs, metrics, and events and flag potential incidents with greater accuracy than static threshold-based alerts.
Modern observability platforms go further, combining metrics, logs, and distributed traces to give teams a unified view of system health, making it much easier to pinpoint where an anomaly originated and act before it becomes a full incident.
-
Alert Noise Reduction
Alert fatigue is a serious problem. One study found that 73% of organizations experienced outages linked to ignored or suppressed alerts. AIOps platforms reduce noise by correlating related alerts, filtering out false positives, and surfacing only the incidents that actually need attention.
-
Automated Triage and Routing
AI can classify incoming incidents, assign them to the right team, and suggest likely resolutions based on historical data, all without human intervention. This cuts down the time between incident detection and the right person working on it.
-
Automated Runbooks and Remediation
AI and automation can also execute runbooks automatically. When a monitoring tool detects a known pattern, such as a server approaching capacity or a service failing a health check, an automated runbook can trigger, run diagnostics, and attempt remediation steps before a human is even paged.
For incidents that need human involvement, AI can surface the right runbook instantly, cutting the time engineers spend searching for the correct steps.
-
AI-Assisted Root Cause Analysis
Rather than manually sifting through logs and metrics, AI tools can analyze large volumes of data and surface likely root causes much faster. One analysis of 100,000 cloud incidents found a 49.7% improvement in root cause identification using AI techniques.
-
Automated Postmortems
Generative AI can draft postmortem reports by pulling from the incident timeline, pulling in relevant metrics, and summarizing what happened. Teams using these tools report saving hours of manual documentation work per incident.
-
Predictive Incident Detection
The most advanced platforms are moving from reactive to predictive, identifying conditions that are likely to cause incidents before they actually do. This shifts the model from responding fast to preventing in the first place.
Across the industry, teams using AI-powered incident management platforms report reducing MTTR by an average of 17.8%, with some implementations achieving up to 30% reductions. The business case is clear: faster resolution means less downtime, and less downtime means lower costs and better user satisfaction.
That said, AI is not a replacement for a solid process. It amplifies a good process and makes a bad one worse. Get the fundamentals right first, such as clear severity levels, escalation paths, and documentation practices, then layer in AI where it adds the most value.
For a broader picture of where the industry is heading, see our overview of ITSM trends.
IT Incident Management Tools
No team manages incidents well with spreadsheets and email threads. The right tools make a significant difference. Here are the main categories to consider:
-
ITSM Platforms
The backbone of any incident management operation. These platforms, often called ticketing systems, handle incident ticket logging, classification, routing, SLA tracking, and reporting.
Look for platforms that support multichannel intake (phone, email, self-service portal), configurable workflows, and strong reporting capabilities. Giva's cloud-based ITSM platform is built for exactly this purpose, with an incident management system designed to give IT teams full visibility across the incident lifecycle.
-
Monitoring and Alerting Tools
Tools that watch your infrastructure, applications, and networks in real time and generate alerts when something goes wrong. Essential for early detection. Examples include infrastructure monitoring platforms and Application Performance Monitoring (APM) tools.
-
Communication and Collaboration Platforms
During a major incident, your team needs a place to coordinate fast. Chat-based collaboration tools integrated with your ITSM platform keep incident response communication in one place and give you a searchable record of decisions made during the response.
-
Knowledge Base Systems
A searchable repository of known issues, resolutions, and workarounds. Either built into your ITSM platform or maintained separately, knowledge management is critical for reducing resolution time and enabling self-service.
-
Reporting and Analytics
Tools that surface incident trends, SLA compliance data, and team performance metrics. These should integrate with your ITSM platform so you are not manually pulling data from multiple systems.
Strategic IT Incident Management for Streamlined Operations
IT incidents are part of running any modern IT environment. You cannot prevent all of them. But with a well-defined incident management process, clear roles, and the right tools, you can make sure your team responds fast, communicates well, and learns from every incident that happens.
The basics matter most: consistent logging, clear prioritization, documented escalation paths, and regular postmortems. Get those right before chasing the latest AI tool or automation trend.
Over time, good incident management builds something more valuable than fast resolution times. It builds trust with users, with leadership, and across your IT team. When people know there is a solid process in place, they have more confidence that problems will be handled, and handled well.
If your current incident management process feels more like improvising than executing, now is a good time to step back and build something better.
IT Incident Management FAQs
-
What is IT incident management?
It's the process IT teams use to detect, respond to, and resolve unplanned service disruptions as quickly as possible, with the goal of restoring normal operations and minimizing business impact.
What often surprises people is how much of it happens before an incident occurs. Teams that handle disruptions well aren't improvising. They're executing a process they already agreed on.
-
What is the difference between an incident and a problem in IT?
An incident is a single unplanned disruption. A problem is the root cause behind one or more incidents. Incident management is about speed. Problem management is slower and investigative.
The question teams struggle with in practice is when to open a problem record. A good rule of thumb: if the same incident recurs more than once or twice without a permanent fix, or if a major incident postmortem surfaces a root cause that can't be resolved immediately, that's your trigger.
-
What is a major incident in IT?
A high-severity incident with significant business impact. Think customer-facing systems down, large numbers of users affected, or a revenue-generating service unavailable.
The key difference from a routine incident isn't just the severity. It's that major incidents require a separate response structure: a dedicated incident manager, executive notifications, and regular status updates. Without that structure defined in advance, teams lose critical time figuring out who's in charge while the clock is running.
-
What are incident severity levels?
Most organizations use a four-level scale, from SEV 1 (complete outage, immediate all-hands response) down to SEV 4 (minor inconvenience, handle during normal business hours).
The definitions aren't the hard part. Consistent application is. The fix is to document specific, concrete examples for each level rather than just descriptions. "A SEV 2 affects a large group of users" is vague enough to mean different things to different people under pressure. "A SEV 2 is when the payroll module throws errors for the finance department" is not.
-
What does MTTR mean and why does it matter?
MTTR (Mean Time to Resolve) measures the average time from when an incident is detected to when it's fully resolved. It's the most commonly tracked incident management metric because it directly reflects how much downtime users experience.
A high MTTR is usually a symptom rather than the root problem itself. It tends to point to gaps in escalation paths, missing runbooks, or on-call coverage issues. Tracking it consistently is how you identify which of those is the actual culprit.
-
How does IT incident management work in small teams?
You don't need a full ITIL implementation to do this well. For smaller teams, the essentials are a simple ticketing system so nothing gets lost in email, agreed severity definitions, a clear escalation path, and some documentation of how you've resolved common issues before.
The temptation is to skip the process entirely when the team is small and everyone knows each other. The problem is that institutional knowledge lives in people's heads. When those people are unavailable during an incident, you feel it immediately.
-
What should you do when an incident crosses ownership boundaries between two teams?
This is one of the most common points of failure in incident response, and most process documentation glosses over it.
The practical answer is to assign a single incident owner immediately, even if the work spans multiple teams. That person doesn't need to be the most technical person in the room. Their job is to coordinate, communicate, and make sure nothing falls through the gap between teams. Without a single owner, both teams assume the other is driving, and neither is.
For recurring cross-team incidents, the longer-term fix is to define ownership boundaries in your CMDB and escalation documentation before the next one hits.
-
When is a workaround good enough, and when do you need a permanent fix?
During an active incident, a workaround is almost always the right first move. The priority is restoring service, not solving the underlying problem. Speed matters more than elegance at that stage.
The question becomes important after the incident closes. A workaround left in place indefinitely is a problem record waiting to be opened. If the workaround is fragile, manual, or requires someone to remember to do something, it needs a permanent fix. If it's stable and low-risk, it may be acceptable short-term while a proper fix goes through the change management process.
Ready to Strengthen Your IT Incident Management? See Giva in Action.
When an IT service goes down, every minute matters. Giva's ITSM software is built to help IT teams log, prioritize, escalate, and resolve incidents faster, with the visibility and reporting you need to keep improving over time.
Giva's incident management platform gives your team a unified workspace to handle every stage of the incident lifecycle, from the first alert to the post-incident review.
With smart routing, automated notifications, and real-time dashboards, your team stays on top of every open incident, and your stakeholders stay informed.
Beyond incident management, Giva's platform covers the full ITSM picture, including:
These all-in-one cloud-based solutions are designed for organizations that care about service quality, ease of use and uptime.
Get a demo to see Giva's solutions in action, or start your own free, 30-day trial today!



Categories: IT