Major Incident Management: Processes, Best Practices, How-To's and Communication Templates
 By Ron Avignone
By Ron Avignone
When it comes to IT incident management, there's no such thing as perfection. No matter how skilled an IT team is, or how well-organized the business is, things break, and incidents happen. Sometimes those incidents are "major" and require a nuanced, rapid response to minimize damage.
Major Incident Management (MIM) is precisely that nuanced approach. MIM relies on speedy decision-making and cross-functional coordination to recover from major incidents. Without a robust Major Incident Management process, recovery may not be possible, and the business's survival is at stake.
In this article, we'll discuss MIM in depth. We'll define what we mean by "major" and compare major incidents to regular incidents. Then, we'll walk you through the Major Incident Management Process, including the various required roles and responsibilities, discuss best practices, highlight pitfalls to avoid, and discuss the inevitable role of AI in MIM.

What Is Major Incident Management?
Major Incident Management is a structured process for responding to and resolving major, high-impact disruptions to IT services that severely affect normal operations, revenue, business reputation, and customer trust.
What Makes an Incident "Major"?
Major incidents are emergencies that affect a large number of users, inflict financial damage, and hurt reputation. The impact of a major incident is wider and deeper than a regular incident. It's not necessarily about how technically complex the issue is, but rather, how much damage it causes the business.
Examples of major incidents:
- A critical business application goes offline
- The data center or cloud service has an outage
- A cybersecurity breach or distributed denial-of-service attack
- Massive slowdowns during business hours
- Integration failures between key software systems
Major Incident vs. Regular Incident |
||
Major Incident |
Regular Incident |
|
Definition |
An incident with widespread impact that requires an urgent, all-hands response |
An unplanned IT interruption that reduces the quality of a service |
Scope of Impact |
Affects many users, services, and/or business functions |
Affects a single user, device, or localized group of people |
Criticality |
High criticality because it threatens revenue, regulatory compliance, safety, and reputation |
Inconvenient but not highly critical, whereby workarounds are used temporarily |
Urgency |
High urgency because rapid decision-making is required to limit the severity of damage |
Handled with regular service-level agreement response and resolution processes |
Priority |
Critical or highest priority |
Low or medium priority |
Management Process |
Managed via a predefined major incident process |
Managed via a standardized incident management workflow |
Required Roles |
Cross-functional teams, including a major incident manager, IT technicians, and sometimes executives |
Normal service desk personnel |
Primary Objective |
Minimize damage and restore critical services as quickly as possible |
Restore routine service while minimizing inconvenience |
Follow-Up Requirements |
Follow up with a post-incident review to identify root causes and improvements for next time |
If recurring, there may be a follow-up, but many regular incidents are completely closed after the fix |
Major Incident Management in ITIL 4
Major Incident Management is a key component of the ITIL 4 framework, which provides best practices for IT service management.
Within ITIL 4:
- Major incidents are treated as a priority subset of incident management
- They trigger a separate, accelerated workflow
- They require dedicated roles and real-time coordination
ITIL emphasizes:
- Rapid service restoration over perfect fixes
- Clear escalation paths
- Structured post-incident reviews
In practice, most modern IT teams adapt ITIL guidance into customized major incident playbooks that reflect their systems, risks, and business priorities.
The 6-Step Major Incident Management Process
When it comes to managing incidents, time is money, literally. IBM's 2024 Cost of a Data Breach report shows the global average cost of a data breach reached 4.88 million USD. And a study conducted by New Relic found that outages cost businesses a median of 33,333 USD per minute of operational shutdown. Further, according to Information Technology Intelligence Consulting (ITIC), 97% of organizations report that a single hour of downtime costs at least $100,000.
Rapid detection of a major incident, like a data breach, is a key factor in minimizing both data loss and financial cost. IT teams should strive to carry out their MIM process within an hour. Within the first 30 minutes would be even better, if possible:
-
Step 1: Detection and Identification
Every incident management process begins with detection. For example, an automated alert, an onslaught of helpdesk tickets, or a panicked email from an involved party. Detecting an incident and determining that it is not an ordinary or routine issue is the critical first step in initiating an MIM process.
-
Step 2: Declaration and Classification
The classification process relies on clear criteria for labeling an incident as major.
ITIL 4 uses an incident priority matrix to standardize this decision. Each incident is rated on two dimensions:
- Impact: How many users, systems, or business functions are affected
- Urgency: How quickly the issue must be resolved to avoid even more damage
High impact combined with high urgency produces a "Priority 1" or "Major" classification and triggers the full MIM workflow. This matrix removes guesswork and helps keep escalation decisions consistent across teams regardless of who is on call.
Then, once the incident is classified, vital information about it must be declared:
- Timestamps
- Affected services
- Impact summary
- Early hypotheses
-
Step 3: Communication and Stakeholder Notification
After a major incident is declared, it must be communicated to all stakeholders. There are four stakeholder groups that make up the major incident team.
- Technical Team: The IT team, consisting of IT technicians, must be notified immediately so they can begin working on the solution.
- Management: Upper management, such as the Chief Information Officer (CIO), should be included for accountability.
- Other Key Stakeholders: Department heads, third-party technical experts, and service-level business management representatives also need to be informed of major incidents and incident updates.
- Users: The users themselves deserve to be notified about service disruptions.
-
Step 4: Team Mobilization and War Room Setup
Having a designated "war room" allows all involved stakeholders to gather in a single space. With everyone in one place, troubleshooting the major incident becomes more collaborative, which can lead to faster recovery.
An important component of any war room is a conference bridge, also known as a conference call. A conference bridge serves as a centralized communication channel among necessary stakeholders.
-
Step 5: Containment and Resolution
Containment is all about restoration of services, not finding a perfect solution. This may include:
- Taking affected systems offline to prevent data loss or further spread
- Activating failover environments or backup infrastructure to restore partial service
- Rolling back a recent change identified as the likely trigger
- Isolating affected network segments during a security incident
- Applying a workaround (e.g., redirecting traffic, disabling a failing feature) to restore access for the majority of users
Once a workaround is established, the incident management team can begin working on a permanent resolution.
The resolution for a major incident should be logged as a change. Logging the incident as a change is good practice because it ensures the response is properly documented and implemented. This will mitigate the chances of the incident resolution being botched, further disrupting important services.
-
Step 6: Post-Incident Review (PIR)
A PIR helps major incident teams reflect on the experience and answer important questions. For example:
- What root cause triggered the major incident?
- Were detection and escalation fast enough?
- Did communication work smoothly across the major incident team members?
- Were existing major incident playbooks effective?
- What parts of the incident process can be automated?
- What part of the incident response can be improved for next time?
An effective PIR avoids playing the blame game or punishing team members. Instead, team members should operate with a growth mindset and be focused on learning from the experience and suggesting systematic improvements.
We'll have more on the PIR below.
Quick Reference Major Incident Management Checklist
For fast-moving incidents, teams often rely on a simple checklist to make sure nothing is missed:
- Identify and confirm incident severity
- Declare major incident and assign incident manager
- Open communication bridge / war room
- Notify stakeholders and users
- Begin containment actions (restore service fast)
- Assign roles across technical teams
- Provide status updates at regular intervals
- Document actions and timeline in real time
- Transition to root cause analysis after stabilization
- Schedule post-incident review
Key Roles and Responsibilities of the Major Incident Team
The Major Incident Team (MIT) comprises first-level tech support, the incident manager, other IT operators, and key stakeholders. Each has distinct roles and responsibilities in successfully resolving the incident:
-
First-Level Technical Support
The first-level technical support consists of service desk technicians. These folks are the first line of defense against major incidents like data breaches and critical disruptions. They are responsible for analyzing incident tickets and escalating them to the incident manager when necessary. First-level service desk technicians may also be involved in implementing resolutions for major incidents.
-
Major Incident Manager
The major incident manager is the owner of the incident. They are responsible for declaring the incident as "major" and ensuring the MIM playbook is followed. Their goal is to resolve the issue as fast as possible. They operate as the point of contact for important information and manage the MIT members.
-
Technical Staff
Technical staff members, like system administrators, network administrators, and IT security staff, make up the technical side of the MIT. They help troubleshoot the major incident. They are responsible for implementing the resolution for the major incident
-
Change Manager
The change manager is the individual responsible for the change implemented to resolve the major incident. They are responsible for authorizing, documenting, and implementing emergency changes. They are also responsible for participating in post-interview reviews.
-
Problem Manager
When a problem ticket is created in response to a major incident, a problem manager takes charge of the ticket. In this role, the problem manager investigates the root cause of the incident. Their goal is to identify the cause so it cannot happen again. Or, at the very least, so the organization is better prepared for the next incident with a similar root cause.
-
Third-Party Experts
Some major incidents may require highly specialized personnel. Oftentimes, these individuals operate as external consultants from third-party vendors. They are identified and called upon by the incident manager. The responsibility of third-party experts is to utilize their expertise to mitigate the impact of the major incident.
-
Communications Lead
Some major incident teams designate a Communications Lead, which is a non-technical role focused entirely on keeping stakeholders informed throughout the incident lifecycle. They draft and distribute status updates, manage communication with end users and business executives, and make sure messaging is consistent, timely, and jargon-free across all channels. Separating the communications function from technical response helps allow the Incident Manager to keep focused on resolution.
Communication During a Major Incident
Major incident communication is vital for keeping the organization and its users aware of the application or service's current state and the estimated time to restore it.
What to Communicate
- A short description in layman's language (without too much jargon) of the major incident. Technical details can be shared immediately after the initial user-friendly briefing.
- Explain who is impacted
- Description of the service impact, for example, an unavailable service feature or general slowness
- The locations affected
- The containment strategy and workaround
- An estimated timeframe for service restoration
Who to Communicate To
- All members of the major incident team, including managers, technical staff, third-party experts, and other company stakeholders, such as department heads. The users themselves also deserve to be notified about service disruptions.
How Often to Communicate
- Major incident updates should be communicated every two hours throughout the incident lifecycle.
- Updates can and should be sent out sooner than two hours when necessary.
8 Major Incident Communication Sample Templates
The following are some sample templates your organization can start with in a major incident:
-
Initial Detection and Internal Alert
Subject: [Internal] Major Incident Declared - [Incident Name]
Intro:
- Status:
- Time detected:
- What we know:
- Potential impact:
- Immediate actions taken:
- Next steps:
- Next update:
Key Contacts:
-
Initial External Notification
Subject: [Subject line]
We are currently investigating an issue affecting [system/service].
- What happened:
- What this means for you:
- What we are doing:
- What you should do right now:
- How we will keep you updated:
We apologize for the disruption.
Signature: [Name / Title]
-
Internal Status Update
Subject: [Internal] Major Incident Update #[n] - [Incident Name]
Intro:
- Status:
- Current time:
- What we know now:
- Actions taken since last update:
- Risks / constraints:
- Next steps:
- Next update:
-
External Status Update
Title: [Status Title]
Intro:
- Status:
- What has changed since last update:
- What we are doing:
- Impact:
- Next update:
-
Regulatory / Authority Notification (Internal Alignment)
Intro:
- Discovery date:
- Estimated affected population:
- Data involved:
- Cause:
- Mitigation actions:
- Responsible teams:
- Required timeline:
-
External Resolution Notice
Subject: [Subject line]
We are providing an update regarding the issue affecting [system/service].
- What happened:
- What we found:
- What we did:
- Support available:
- What you can do:
We regret any inconvenience caused.
Signature: [Name / Title]
-
Internal Resolution Summary
Subject: [Internal] Major Incident Resolved - [Incident Name]
Intro:
- Status:
- Incident window: [Start-End]
- Scope:
- Root cause
- Key remediation actions:
- Next step:
-
PIR Summary Note
Subject: Post-Incident Review Outcomes - [Incident Name]
Body:
- Root cause:
- What worked well:
- Areas to improve:
- Agreed actions:
-
Incident Recap
The incident recap should provide a concise recap of the major incident. This includes:
- An incident description: What happened, and when did it start?
- Impact summary: The severity based on affected systems, services, and users
- Chronological timeline of the incident response
-
Root Cause Analysis
The root cause analysis in a PIR should go beyond simply identifying the immediate issue. The analysis should identify the issue itself and the "why" behind the incident.
Important questions to ask include:
- What were the factors that contributed to the incident?
- Was there a breakdown that allowed the issue to escalate?
- Could the incident have been prevented?
-
Incident Response Evaluation
The PIR should also evaluate the response process itself. This includes paying attention to factors like:
- Response time: Gathering major incident metrics and KPIs
- Communication: Was the communication amongst the MIT effective?
- Escalation: Was the escalation playbook followed effectively? Were there delays in engaging the correct stakeholders?
-
Actionable Recommendations
The root cause analysis and incident response evaluation will inevitably highlight weak points in the MIM process. Therefore, there needs to be actionable changes to improve the process for next time.
- Process improvements: Modifying old processes or creating new ones to streamline the incident management process
- Technology enhancements: Using new tools to improve monitoring systems
- Additional training: To improve response capabilities
-
Lessons Learned
Documentation of the important lessons that were learned from the incident, like what components worked well and which did not. Reflecting on the process in this way encourages continuous improvement.
-
Follow-Up Actions
Schedule follow-up meetings and reviews to ensure that the actionable recommendations are truly being implemented.
- What happened?
- When did it start?
- What systems, users, or services were impacted?
- What caused the incident?
- Why did it happen?
- Could it have been prevented?
- Was the response fast enough?
- Was escalation effective?
- Did communication work across teams?
- What should change going forward?
- What actions will prevent or reduce impact next time?
- What did we do well?
- What should we avoid or improve in the future?
- Are action items being completed?
- How will we verify improvements are effective?
-
No Clearly Defined MIM Process
Teams are forced to improvise when they lack a clearly defined MIM process. And improvisation is the last thing you want during a major incident. Without clear protocols, MTTA and MTTR metrics will skyrocket, and CSAT scores will inevitably plummet.
-
Fragmented Communication
Emails get lost, and messaging chats don't include everyone who needs to be involved. Poor communication leaves stakeholders in the dark. Technical jargon confuses business executives. And a lack of communication erodes customer loyalty and trust.
-
Striving for Perfection, Not Restoration
In the wake of an emergency incident, rapid stabilization or restoration is the priority, not perfection. Striving for perfect, long-term fixes right away takes too much time and ultimately increases the overall incident duration metric.
-
Lack of Major Incident Response Training
A major incident response playbook may exist, but if the MIT hasn't taken the time to rehearse their roles and responsibilities, they won't fully understand how to respond when real incidents occur.
-
Too Many Stakeholders in the War Room
Major incident teams should be streamlined groups of people with clearly defined roles. Once they get into the war room, everyone should know their role and responsibilities. When you get too many stakeholders in the war room, they can end up with messy communication, context switching, and a lack of leadership.
-
Skipping the Post-Incident Review
The PIR is the most valuable component of the major incident response process. If you skip the PIR, you eliminate the opportunity to identify the root cause, address recurring issues, fill process gaps, and implement additional training for IT personnel.
-
Define Clear and Concise MIM Criteria
Before a major incident can occur, you must document:
- What counts as a major incident
- Who can declare it "major"
- Who acts as the major incident manager
- The step-by-step playbook, from detection through the PIR
-
Build and Rehearse Major Incident Playbooks
Building a step-by-step incident management process playbook is one thing. But rehearsing the playbook is where the real value is derived. A playbook should exist for software outages, database failures, and ransomware attacks. And the MIT should run regular simulations to ensure they're prepared for the real thing.
-
Give Real Authority to a Single Major Incident Manager
The most effective major incident response teams operate under a clearly defined incident manager. The major incident manager should have leadership rights over priorities, communications, and emergency changes.
-
Separate Rapid Restoration from Root-Cause Analysis
Once again, rapid restoration is the priority. After the team has established a worthwhile workaround, responsibilities for deeper root-cause analysis can be assigned to the Problem Manager.
-
Operate With a Growth Mindset
In the moment, major incidents are painful. But with the correct mindset, they can also be enlightening. So, instead of finger-pointing and blaming, the best MIT's operate with a growth mindset so they can learn from the experience.
-
Review and Continuously Improve MIM
Continuous improvement in MIM comes from tracking metrics such as MTTA, MTTR, the number of major incidents, and the recurrence rate. Structured post-incident review processes are also vital for updating playbooks, training IT personnel, and automating certain MIM components.
- Faster detection and triage: AI-driven monitoring, or AIOps, uses machine-learning-based anomaly detection to spot issues before humans notice, cutting Mean Time to Detect (MTTD).
- Shorter diagnosis: AI correlates events across systems, performs log clustering and dependency analysis, and uncovers root causes. This transforms hours of manual investigation into minutes, thereby decreasing MTTR.
- More effective communication: Generative AI is increasingly used to draft status updates, customer emails, and internal summaries from live incident data. This helps teams communicate faster and more consistently under pressure.
-
What is the difference between an incident and a major incident?
An incident is any unplanned service disruption. On the other hand, a major incident is a high-impact disruption that affects critical services or many users and triggers an urgent, special response.
-
How do you declare a major incident?
You declare a major incident when an issue meets predefined criteria for impact and urgency. Once you meet those criteria, an authorized person, usually the Major Incident Manager, elevates it to the major-incident process, activating the major incident team and playbook.
-
What does a major incident manager do?
The major incident manager leads the response from start to finish. This is, from the initial detection of the incident through the PIR. Throughout the process, they coordinate technical teams, filter distractions, make decisions, and ensure timely updates until service is restored and the record is closed
-
What is a post-incident review?
The post-incident review, or PIR, is a structured, usually blameless meeting held after a major incident. The goal is to reconstruct what happened, identify root causes, and agree on actions to prevent recurrence in the future.
-
How does major incident management relate to problem management?
Major incident management focuses on rapidly restoring service through containment and convenient workarounds. On the other hand, robust problem management digs into underlying causes and permanent fixes so the same kind of major incident is less likely to happen again.
The Post-Incident Review
In the aftermath of a major incident, the priority is to restore services as rapidly as possible. Once a resolution has been established, it is time for the Post-Incident Review (PIR), also sometimes referred to as the Post-Major Incident Review (PMIR).
The PIR is a formal meeting where key stakeholders identify the root cause, assess the incident management process, share insights, and document lessons learned. The overarching goal of the PIR is to walk away with a strategy for preventing similar issues in the future.
The 6 Critical Components of an Effective PIR
Quick Reference Major Incident Post-Incident Review Template
Component |
What to Include |
Key Questions to Answer |
Incident Recap |
Brief description of the incident, start time, impacted systems/services, and overall severity. Include a high-level timeline. |
|
|
Root Cause Analysis |
Identify the underlying cause(s) and contributing factors (technical, process, or human). Go beyond surface-level symptoms. |
|
Incident Response Evaluation |
Review how the team handled detection, escalation, communication, and resolution. Include metrics like Mean Time to Acknowledgement (MTTA) and Mean Time to Resolve (MTTR). |
|
Actionable Recommendations |
Specific improvements to processes, tools, monitoring, or training. Assign owners and timelines. |
|
Lessons Learned |
Summary of what worked well and what didn't during the incident response. |
|
Follow-Up Actions |
Scheduled follow-ups to ensure improvements are implemented and tracked over time. |
|
Major Incident Management Metrics
Major incident metrics are the key performance indicators that a major incident team can track to understand how fast, how often, and how effectively the team handled the incident response process:
Major Incident Management Metrics |
||
Speed Metrics |
||
Mean Time to Detect |
MTTD |
The average time from when a major incident occurs to when it is detected |
Mean Time to Acknowledgment |
MTTA |
The average time from detection to when the team acknowledges and begins working on the incident |
Mean Time to Resolve |
MTTR |
The average time from detection to complete resolution |
Frequency Metrics |
||
Major Incident Frequency |
MIF |
How many major incidents occur in a given time period (ie. monthly, quarterly, annually) |
Mean Time Between Major Incidents |
MTBMI |
The average time between major incidents |
Quality Metrics |
||
Service Level Agreement (SLA) Compliance for Major Incidents |
SLA Comp % |
A percentage of major incidents resolved within the agreed recovery time according to the SLA |
Customer Satisfaction |
CSAT |
The perceived satisfaction of users or customers with how the incident was handled |
Recurrence Rate |
RR |
The rate at which issues linked with a major incident recur |
Operational Impact Metrics |
||
Total Business Impact Per Major Impact |
The estimated financial loss per major incident, combining downtime cost, lost revenue, and recovery spend |
|
Number of Critical Services Affected |
The number of key applications or customer journeys that were impacted during a major incident |
|
Incident Duration |
The total time users were affected |
|
Common Mistakes in Major Incident Management
An effective incident management procedure is the key to a business's success, customer satisfaction, and reputation. By avoiding the following common mistakes, organizations can ensure their incident response process remains high quality:
Best Practices for Building MIM Capability
Mature MIM capability doesn't occur overnight. Strengthening how your organization responds to major incidents comes from years of playbook preparation and rehearsals that exemplify best practices for major incidents:
AI and Automation in Major Incident Management
AI technology is reshaping MIM by automating incident detection and triage, diagnosis, and communication among major incident team members.
However, there is an ironic "AI paradox" in incident management. That is, IT teams using AI tools often deal with more incidents, not fewer. That's because newer AI tools increase system complexity. Therefore, it's become clear that the real value of AI is not eliminating major incidents entirely, but reducing the unplanned downtime and organizational costs associated with each incident.
Major Incident Management FAQs
Major Incidents Are Unavoidable, and a Streamlined MIM Process Is Critical for Recovery
Major incidents that result in costly unplanned downtime will happen. However, what follows the incident does not have to be chaotic or disorganized. With a clear MIM process, MITs can focus on rapid containment and safe recovery. This includes well-organized playbooks for various scenarios, defined roles, effective communication, and automation.
Ready to Strengthen Your IT Incident Management? See Giva in Action!
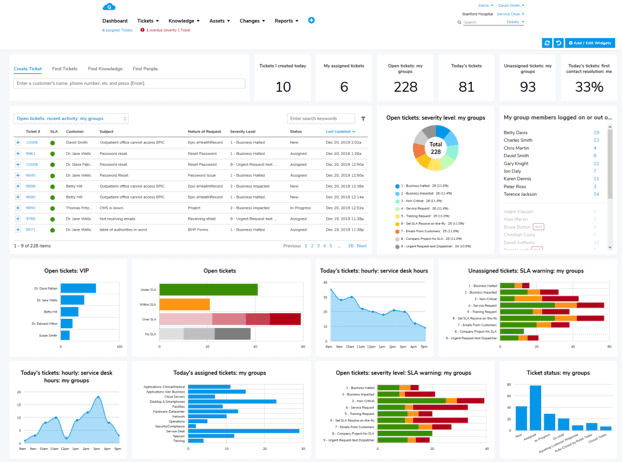
When an IT service goes down, every minute matters. Giva's ITSM software is built to help IT teams log, prioritize, escalate, and resolve incidents faster, with the visibility and reporting you need to keep improving over time.
Giva's incident management platform gives your team a unified workspace to handle every stage of the incident lifecycle, from the first alert to the post-incident review.
With smart routing, automated notifications, and real-time dashboards, your team stays on top of every open incident, and your stakeholders stay informed.
And for major incidents, Giva's Tsunami Tickets feature is an innovative solution designed to manage multiple tickets linked to a single event, often used during emergencies or major outages. It allows agents to concurrently update all linked tickets, ensuring efficient communication and resolution during high-pressure situations.
Beyond incident management, Giva's platform covers the full ITSM picture, including:
These all-in-one cloud-based solutions are designed for organizations that care about service quality, ease of use and uptime.
Get a demo to see Giva's solutions in action, or start your own free, 30-day trial today!



Categories: IT, Help Desk