Post-Incident Review (PIR): The Complete How-To's and Best-Practices Guide Plus Report Template
Every IT team knows the feeling. The outage is over, the system is back up, and everyone is exhausted. The instinct is to move on. But moving on is exactly how the same incident happens again six months later.
That structured conversation is a Post-Incident Review, or PIR. Done well, it turns an outage into a concrete improvement. Your team examines what broke, why, and what needs to change to prevent a repeat. Done poorly (or skipped entirely), it leaves the same vulnerabilities in place.
This post covers what a PIR is, which incidents warrant one, how to prepare and run the meeting, what the written report should include, and, critically, how to make sure the findings actually lead to change rather than sitting in a shared doc no one revisits.

What Is a Post-Incident Review?
A Post-Incident Review (PIR) is a structured process, typically resulting in a written report, that examines why an IT incident occurred, how it was handled, and what changes will prevent recurrence.
The PIR format varies by organization, but the key elements stay consistent. Every effective review includes:
- A timeline of the key events
- A root cause analysis
- An impact assessment
- An evaluation of the response
- Assigned action items with clear owners
The goal is learning, not judgment. Most teams conduct PIRs within 48 hours of incident resolution, while the details are still fresh.
In ITIL 4, PIRs are a standard step in the Major Incident Management process. They feed directly into Problem Management, where the root causes identified in the review can be documented and tracked toward permanent resolution.
Post-Incident Review vs. Postmortem vs. Root Cause Analysis
These three terms are often used interchangeably, but they refer to different things. You may also see "after-action review," "hotwash," or "retrospective" used to describe the same process, depending on the industry and organizational culture:
-
Post-Incident Review (PIR)
The full organizational process that follows an incident. It involves:
- Gathering the right people
- Working through the incident timeline
- Analyzing causes and assessing impact
- Evaluating the response
- Producing action items with assigned owners
A PIR is a meeting plus a document plus a follow-up commitment.
-
Postmortem
A term that comes from software engineering and Site Reliability Engineering (SRE) culture. A postmortem is essentially the same thing as a PIR, and the words are used interchangeably across most IT organizations. Some teams prefer "post-incident review" because "postmortem" implies something died, which can set a negative tone before the meeting even starts.
-
Root Cause Analysis (RCA)
A specific analytical technique used inside a PIR, not a replacement for one. Root cause analysis focuses narrowly on identifying the underlying cause of the incident. The 5 Whys method is the most common approach. RCA is a step within a PIR, not a parallel process.
Here is a quick comparison:
|
Post-Incident Review |
Postmortem |
Root Cause Analysis |
Scope |
Full incident lifecycle: causes, impact, response, action items |
Same as PIR (terms used interchangeably) |
Narrow: finding the root cause only |
Focus |
Learning and improvement across people, process, technology |
Same as PIR |
Causal chain behind the incident |
Output |
PIR report, action items, handoff to problem management |
Postmortem document, action items |
Root cause statement, corrective actions |
Typical Context |
ITIL/ITSM organizations, IT operations teams |
DevOps, SRE, software engineering teams |
Used inside a PIR or postmortem |
Why Post-Incident Reviews Matter
First off, incidents are expensive. ITIC's 2024 Hourly Cost of Downtime Survey, which polled over 1,000 firms worldwide, found that the average cost of a single hour of downtime exceeds $300,000 for the majority of mid-size and large enterprises. For some verticals, including banking, healthcare, and retail, that figure is substantially higher.
The financial case for PIRs is straightforward. If a 90-minute review prevents even one repeat incident, it pays for itself many times over.
The stronger argument, though, is systemic. Organizations that consistently review their incidents and act on what they learn get faster at detecting problems, faster at resolving them, and better at preventing the same issues from recurring.
Conducted consistently, a PIR delivers four categories of benefit:
- Continuous improvement: Each incident becomes a documented learning opportunity rather than a disruption to move past.
- Reduced future risk: Root cause analysis identifies systemic vulnerabilities before the same incident can recur.
- Improved response: Teams that review their incidents build better detection, diagnosis, and communication capabilities over time.
- Transparency: The PIR report creates documented records for stakeholders, leadership, and, where required, legal and compliance teams.
The Case for a Blameless Approach
The most common reason post-incident reviews fail to produce honest findings is blame. When team members worry that speaking candidly will result in consequences, they give the sanitized version of events. Sanitized versions don't reveal what actually went wrong.
The blameless approach, popularized by Google's Site Reliability Engineering (SRE) team and rooted in the concept of "just culture" from aviation and healthcare, starts from the premise that people make reasonable decisions given the information they had at the time. The goal of the PIR is not to evaluate whether someone made the right call. It is to understand what information, tools, or processes would have produced a better outcome.
One point worth clarifying: Blameless does not mean accountability-free. Action items still have owners. Deadlines still apply. Standards still matter. The difference is that accountability is directed forward, at systems and processes, not backward at the individual who happened to be on call when the incident hit.
The Action Item Completion Problem
There is a pattern that plays out in IT organizations across every industry. A team runs a solid Post-Incident Review, produces a list of action items, and then watches most of them quietly disappear into a backlog as feature work takes priority. The review felt productive, but the follow-through didn't happen. Six months later, a nearly identical incident occurs.
Research consistently shows that a significant share of PIR action items are never completed. Across most organizations, the majority of improvement work identified in reviews doesn't make it to implementation. The problem is that improvement work competes poorly against new feature development when it lives in a separate document rather than in the same work management system the team uses every day.
This is the most important insight in this article: A Post-Incident Review that doesn't produce implemented changes is just a meeting.
The rest of this article covers both how to run a good review and how to structure the follow-up so that what you learn actually leads to improvement.
Which Incidents Need a Post-Incident Review?
Running a full post-incident review after every ticket is neither practical nor useful. The goal is to apply the process where it will have the most impact:
Severity-Based Triggers
The most reliable approach is to set a severity threshold that automatically triggers a PIR. Most organizations apply incident severity levels (Sev-1, Sev-2, Sev-3, and so on), and a common policy is to require a PIR for all Sev-1 and Sev-2 incidents. Major incidents always qualify.
Beyond severity, a few other conditions should also trigger a review, even for lower-priority incidents:
- The incident affected customers or resulted in an SLA breach
- The incident was caused by a change or deployment (a failed change should always be reviewed)
- The same type of incident has occurred before (a repeat incident signals that a prior fix didn't hold)
- The response was notably slow, disorganized, or involved significant escalation confusion
- The incident revealed a gap in monitoring, runbooks (step-by-step documented response procedures), or on-call coverage
Teams that skip PIRs for lower-severity incidents but see the same low-severity issue repeat three times are often missing a systemic pattern. A lightweight review, shorter and less formal, is better than no review for recurring patterns.
How Soon After Resolution?
Timing is important. The closer the review is to the incident, the more detail the team will remember and the more accurate the timeline reconstruction will be.
The standard recommendation is to hold the PIR within 24 to 48 hours of resolution for major incidents. Some organizations, including teams following IT Revolution's incident management framework, aim to hold the review within 24 hours. The outer limit is five business days, because beyond that, important details start to fade.
One practical exception applies when the incident resolution involved an extended overnight response. Give the team a recovery window before convening the review. A team that worked through the night is not in the right mental state for a productive conversation the next morning. A brief delay to let people rest is worth it.
How to Prepare for a Post-Incident Review
Preparation is what separates a productive PIR from a rambling discussion. The meeting itself typically runs 60 to 90 minutes. The quality of that time depends heavily on what happens before it.
Who Should Attend
For what IT Revolution calls a Local PIR (the operational review closest to the incident), keep attendance tight. The main attendees include:
- The incident commander, who led the response
- The scribe or note-taker from the incident
- Engineers and responders who were directly involved in diagnosis and resolution
- System or service owners for the affected components
- A problem manager or change manager, if the incident has obvious problem or change implications
Senior leadership and customer representatives should generally not attend the Local PIR. Their presence changes the dynamic and can undermine the psychological safety needed for honest discussion. If leadership needs a summary, produce one separately after the review is complete.
For technically complex incidents involving specialized infrastructure or custom systems, one or two subject matter experts from the relevant domain may be invited even if they weren't part of the original response team. Their technical context can be essential for an accurate root cause analysis.
For incidents with broader organizational impact, such as a major outage affecting multiple services or a large customer segment, a Global PIR or lessons-learned forum can share findings more widely. That is a separate, higher-level event, not the operational review itself.
Roles to Assign Before the Meeting
Four roles should be assigned before anyone sits down:
- Facilitator: Guides the discussion, enforces the blameless ground rules, and ensures the conversation stays focused and constructive. Ideally, this is someone with enough seniority to command the room but who was not personally in the hot seat during the incident. A neutral facilitator is the single biggest determinant of PIR quality.
- Note-Taker: Documents findings, decisions, and action items in real time during the meeting. This role is distinct from the facilitator, since one person cannot do both well.
- Timekeeper: Watches the clock and signals when the group is spending too long on any one section. A 90-minute meeting that runs to two hours often means the last 30 minutes (where action items get defined) gets rushed.
- PIR Document Owner: Responsible for drafting the written report after the meeting. This person ideally has the technical knowledge to reconstruct details accurately and the organizational context to frame recommendations clearly.
What to Collect Before You Meet
The person drafting the pre-meeting materials should gather:
- A complete incident timeline with exact timestamps, pulled from monitoring tools, ticketing systems, and chat logs
- The original incident record and ticket history
- Alert and notification logs showing when detection happened and who was notified
- Communication records such as status page updates, stakeholder messages, incident escalation notifications
- Any runbook or documented response procedure that was (or should have been) used
- An initial impact summary noting the number of users affected, services disrupted, total duration, SLA status
Sending this pre-read to attendees before the meeting is worth the extra step. Teams that walk into a PIR cold spend the first 20 minutes reconstructing the timeline together. Teams that receive a pre-read spend those 20 minutes analyzing it.
How to Run the Post-Incident Review: A 6-Step Process
The meeting follows a consistent structure, even if the specific time spent on each section varies by incident severity and complexity:
-
Step 1: Review the Incident Timeline
Start by walking the group through the full sequence of events. The timeline should begin when the business was first impacted, not when the first ticket was opened. These two moments are often different, and the gap between them is often one of the most important findings in the review.
As the facilitator walks through the timeline, the group should flag any moment where the response paused, escalated unexpectedly, or where a key decision was made. These are the moments the review will return to in Steps 2 and 4.
-
Step 2: Identify the Root Cause
Once the timeline is clear, the group moves to root cause analysis. The most widely used techniques are the 5 Whys and the fishbone diagram (also called the Ishikawa diagram). The 5 Whys starts with the initial failure and asks "why did this happen?" repeatedly, working back through each cause until reaching a systemic gap that can be addressed. Fishbone diagrams map categories of potential causes, such as people, process, tools, and environment, and their contributing factors visually, which is useful when multiple contributing factors are suspected.
One important nuance applies when the immediate cause appears to be human error. The 5 Whys should keep going. Human error is almost always a symptom of a deeper systemic gap, such as missing training, an ambiguous runbook, inadequate tooling, or a process that required a decision no one was clearly empowered to make. Stopping at human error produces no actionable fix.
Here is a simple example of how this works in practice:
- Why did the application go down? Because the database ran out of connections.
- Why did the database run out of connections? Because a spike in traffic exceeded normal load.
- Why wasn't the spike anticipated? Because there was no load test before the new feature deployed.
- Why was there no load test? Because the deployment process doesn't include a load testing step for this type of change.
- Why not? Because the runbook was written before load testing was part of the team's standard practice and has never been updated.
The fifth answer is actionable. Updating the deployment runbook to include load testing for this change type is something the team can actually do. "The database ran out of connections" is not.
-
Step 3: Assess the Business and User Impact
The impact section quantifies what the incident cost, in concrete terms that connect the technical failure to business reality. The key figures to capture are:
- Total number of users or customers affected
- Specific services or features that were unavailable
- Duration of the outage or degradation
- Whether any Service Level Agreements (SLAs) were breached, and by how much
- Downstream effects such as customer complaints, tickets opened, revenue impact if measurable
Documenting impact thoroughly serves two purposes:
- It helps prioritize remediation, since an incident that affected 50,000 users deserves a different urgency level than one that affected 50 internal users
- It also creates a record that makes the business case for preventive investments
-
Step 4: Evaluate the Response
This step reviews how the team performed, not to assign grades, but to find improvement opportunities. The facilitator should guide the group through four questions:
- Detection: How did we find out about the incident? Could we have detected it sooner, and if so, how?
- Diagnosis: Did the responders have the information they needed? Were there data gaps or monitoring blind spots that slowed diagnosis?
- Communication: Were the right people and stakeholders kept informed? Were updates timely and clear?
- Resolution: What would have helped resolve this faster? Were there tools, runbooks, or escalation paths that should have been available but weren't?
Three metrics are particularly useful here:
- Mean Time to Detect (MTTD) measures how long from the start of the incident until it was identified
- Mean Time to Acknowledge (MTTA) measures how quickly the right responders were engaged and confirmed they were working the problem
- Mean Time to Resolve (MTTR) measures how long from identification to full resolution.
Tracking all three across incidents over time shows where delays are grouped and whether the team is improving.
-
Step 5: Define Action Items
This is the step where most PIRs either succeed or fail. Action items (also called corrective actions in ITIL terminology) should be:
- Specific: "Add load testing to the deployment runbook for capacity-impacting changes" not "improve our deployment process"
- Assigned: One named owner per action item, not a team or a role
- Time-bounded: A due date, not an aspiration
- Scoped: Realistic given the team's current workload, so they can actually be completed
The most important operational decision here is where action items live. If they go into a shared doc or a separate PIR tracking spreadsheet, they will compete poorly against the regular work that lives in Jira, Azure DevOps, or whatever system the team uses daily. Track PIR action items in the same place as everything else, so they have to compete fairly for engineering time and stay visible.
-
Step 6: Document and Share Findings
The PIR document owner drafts the written report within 24 to 48 hours of the meeting. The report preserves the discussion for team members who weren't present, creates a searchable record for future incidents of the same type, and provides the summary that leadership or affected stakeholders may need.
For major incidents that affected customers, some organizations publish a public-facing post-incident report on their status page or blog. AWS and Google, for example, regularly publish post-incident summaries after significant service disruptions. Public reports typically include what happened, what was impacted, when it was resolved, and what the team is doing to prevent recurrence, without the internal operational detail of the Local PIR.
Template for What a Post-Incident Review Report Should Include
The PIR document should be clear and structured enough that someone not in the meeting can understand what happened and what is being done about it. It should not be so long or formal that filling it in becomes the goal instead of the learning.
A complete post-incident review report should include:
Incident Summary
A short paragraph (3 to 5 sentences) describing what happened, when it started, when it was resolved, and the top-line impact. It should be written in plain language so non-technical stakeholders can follow it.
Impact Statement
Quantified figures, including number of users or customers affected, specific services that were down, total duration of the incident, and SLA breach status.
Incident Timeline
A chronological list of key events with exact timestamps. Start from when the business impact began, not when the first alert fired or ticket was opened.
Root Cause Analysis
The findings from the 5 Whys or other structured analysis. Identify the root cause and any significant contributing factors. Distinguish between the root cause (the systemic reason) and the trigger (what set off the incident on this particular day).
Response Evaluation
- What went well
- What slowed the response
- Gaps in detection, tooling, runbooks, or communication
Include MTTD and MTTR figures.
Action Items
Each item needs a description of the change required, one named owner, a due date, and a priority rating. No shared ownership and no open-ended due dates.
Lessons Learned
A brief summary of the key takeaways from the review:
- What would the team do differently?
- What should other teams across the organization know about this incident?
Keep the report focused. A PIR document that runs 15 pages tends to be written for the documentation requirement, not for the reader. Most effective PIR reports are 2 to 4 pages.
Also, most teams benefit from a consistent PIR that covers these sections in order as a template, so reviews follow the same structure regardless of who runs them and findings are easy to compare across incidents over time.
9 Post-Incident Review Best Practices
-
Establish Blameless Ground Rules Before Every Review
Open every PIR by stating explicitly that this is a learning conversation, not a performance review. Individual decisions are evaluated based on the information available at the time, not on hindsight.
-
Start the Timeline From Business Impact, Not Ticket Creation
The gap between when the business was affected and when IT was aware of it is often a significant finding on its own. Starting the timeline at ticket creation hides that gap.
-
Use a Structured Root Cause Technique, Not Intuition
The 5 Whys forces the group to dig past the obvious symptoms. Without a structured method, teams often stop at the most recent human action ("someone clicked the wrong button") rather than the systemic gap that made the error possible.
-
Keep the Local PIR Attendance Small
Larger meetings are less candid. The people who need to be in a Local PIR are those with direct knowledge of the incident. Others can receive a summary.
-
Track Action Items in Your Existing Work Management System
If your team uses a ticketing platform for daily work, PIR action items belong there too. Separate tracking systems create separate priorities, and improvement work always loses that competition.
-
Review Outstanding PIR Action Items Regularly
A monthly engineering review that checks the status of open PIR action items catches items that have gone stale. Without a regular check-in, items that didn't get done this sprint quietly get pushed to next sprint, and then to next quarter.
-
Share Findings Broadly Through a Lessons-Learned Forum
The Local PIR is for the team closest to the incident. A Global PIR or a monthly lessons-learned forum spreads the learning to the rest of the engineering organization, so teams working on different systems benefit from what another team just went through.
-
Review Your Past Reviews
Periodically audit closed PIR action items to check whether the changes were implemented and had the expected effect. If a PIR from six months ago recommended updating an alert threshold, and the same threshold is still creating false negatives, the review produced an insight that never became an improvement.
-
Use AI Tools to Accelerate Preparation, Not to Replace the Conversation
AI-assisted incident management tools can now auto-generate draft postmortems from incident timelines, chat logs, and monitoring data, reducing the time needed to prepare the pre-read.
Some tools can also flag patterns across historical incidents that humans might miss. These capabilities are genuinely useful for preparation and pattern analysis.
The conversation itself, however, still requires human judgment. An AI-generated draft is a starting point, not a conclusion. Teams that skip the live discussion in favor of an AI-produced report miss the collaborative sense-making that turns a review into a learning event.
Post-Incident Review and ITIL: The Connection to Problem Management
In ITIL 4, a Post-Incident Review is not the final step in the incident lifecycle but the handoff point. The findings from a PIR feed into two other ITIL practices that carry the work forward.
PIR and Problem Management
Problem Management addresses the root causes that incident management reveals. When a PIR identifies a recurring root cause, such as a known software defect, a configuration gap, or an architectural weakness, that finding should become a problem record.
The problem record lives beyond the incident. It tracks the known error, the available workaround, and the path to a permanent fix. Problem managers own the problem record and are responsible for pushing toward resolution. This is the structural mechanism that keeps a PIR from being a one-time event. It creates a persistent, tracked obligation to fix the root cause.
PIR and Change Management
Many PIR action items will require a change to infrastructure, configuration, or code. In ITIL terms, that means a change request. Those changes go through the ITIL change management process, which means they are assessed, scheduled, and reviewed, rather than deployed under pressure at 2 a.m. the way the original incident may have been.
This connection matters for one practical reason: Teams that skip the change management handoff after a PIR often find that the fix they deploy after the review introduces a new incident. A structured change process is part of what makes PIR action items stick safely.
The Full Loop
The complete ITIL loop works like this:
- An incident occurs and is resolved through IT incident management
- The PIR examines what happened and produces findings and action items
- Those findings feed into problem management (root cause tracking) and change management (remediation)
- The changes are deployed, tested, and reviewed
- Future incidents of the same type are less likely, and when similar incidents do occur, the response is faster because the team has documented playbooks
Teams that treat the PIR as the end of the process miss the second half of that loop. The review is where learning is captured, and problem and change management are where it gets implemented.
Post-Incident Review FAQs
-
What is the difference between a post-incident review and a postmortem?
The two terms mean essentially the same thing. Both refer to the structured review process conducted after an incident is resolved.
"Postmortem" is more common in DevOps and Site Reliability Engineering (SRE) contexts, and "Post-Incident Review" or PIR is more common in ITIL-aligned IT operations teams. Some organizations prefer PIR because "postmortem" implies someone was at fault, which can conflict with the blameless culture they are trying to build.
If you see either term used in the same organization, they are almost certainly referring to the same process.
-
Who should attend a post-incident review?
For a Local PIR, attendance should be limited to people with direct knowledge of the incident. This typically includes the incident commander, the scribe, engineers who worked the response, and system or service owners for the affected components. A problem or change manager may attend if their domain is clearly implicated.
Senior leadership and customer representatives should generally not attend the Local PIR. Their presence can suppress candid conversation and shift the focus from learning to reporting. A summary for those stakeholders can be produced from the PIR report after the meeting.
-
When should you conduct a post-incident review?
A PIR should be held within 24 to 48 hours of incident resolution for major or high-severity incidents. The outer limit is five business days. Beyond that, team members' recollections become less reliable and details from monitoring logs and chat history get harder to piece together.
If the incident required a long overnight response, give the team a short recovery window before convening the review. Scheduling it for the morning after a 12-hour outage response leads to a meeting where people are too tired to think clearly.
-
How long does a post-incident review take?
Most post-incident reviews run 60 to 90 minutes. Complex major incidents, or incidents involving multiple teams or external dependencies, may take longer. For lower-severity incidents where a lightweight review is appropriate, 30 to 45 minutes is often sufficient.
Meetings that consistently run over two hours are usually a sign that either the scope is too broad (trying to resolve root causes in the meeting rather than assigning that work as action items) or that the facilitator is not keeping the discussion on track.
-
What is the difference between a post-incident review and a root cause analysis?
Root Cause Analysis (RCA) is a specific analytical technique used within a post-incident review. The 5 Whys is the most common RCA method, starting with the initial failure and asking "why?" repeatedly until the team reaches a systemic cause that can actually be addressed.
A PIR is a broader process that includes RCA as one step. Beyond finding the root cause, a PIR also assesses the business impact, evaluates the response, defines action items, and produces a written report.
You can run an RCA without running a PIR, but you should not run a PIR without including a structured root cause analysis.
-
What happens after the post-incident review is complete?
The PIR document owner publishes the written report within 24 to 48 hours of the meeting. Action items are entered into the team's work management system with assigned owners and due dates. Findings that identify a recurring root cause are escalated to problem management as a problem record. Any remediation changes go through the change management process.
From there, the team's responsibility is follow-through. A designated person should track open PIR action items and flag any that are at risk of slipping. Most organizations do this in a regular engineering review meeting. If action items consistently go unimplemented, the PIR process has a follow-through problem, which is typically a prioritization and visibility issue, not a meeting quality problem.
Related Giva Resources
- ITSM Automation Fully Examined + 10 Use Cases and How-To's
- Incident Classification Fully Examined: How-To's & Best Practices
- Who Does What? How to Quickly Adopt ITIL Roles and Responsibilities
- Fully Examining ITIL Processes: Types and Real-World Examples
- Top 10 ITSM Best Practices Plus Action Items for CIOs and IT Leaders
Making Your Post-Incident Review the Start of Real Improvement
A Post-Incident Review is not a formality to check off after a major outage. It is the point in the incident lifecycle where your team has a real opportunity to make the next incident less likely, or at least less damaging. The meeting itself is the easy part.
The harder part is the follow-through. Most IT organizations that run PIRs know what they are supposed to do. The gap is in making sure that what the review reveals actually gets built into the systems, runbooks, and processes that govern the next incident. That means tracking action items in the right place, reviewing them regularly, and connecting PIR findings to problem management and change management so nothing falls through the cracks.
If your team is running reviews but seeing the same types of incidents recur, the review process isn't the problem. The action item pipeline is. Fix the pipeline, and the reviews will start to pay off.
How Giva Supports Your Post-Incident Review Process
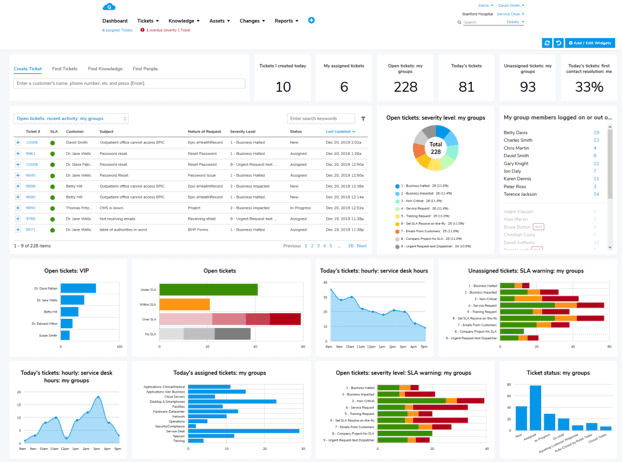
Post-Incident Reviews are only as effective as the systems that support them. To run a consistent, well-documented review process, IT teams need a platform that captures the full incident record, including the timeline, responders, communications, and resolution steps, in one place. That record is the raw material for every PIR.
Giva's IT Service Management (ITSM) platform gives IT teams a structured way to manage incidents from detection through resolution and into the post-review phase. Incident records, Service Level Agreement (SLA) data, and communication logs are captured automatically, so your PIR team isn't piecing together a timeline from memory and chat messages.
With smart routing, automated notifications, and real-time dashboards, your team stays on top of every open incident, and your stakeholders stay informed.
Giva is also seamlessly integrated with an IT Change Management module for workflows that turn PIR findings into lasting improvements. When a review identifies a root cause that needs a permanent fix, Giva keeps that work visible and trackable alongside the rest of the team's priorities.
And working hand in hand with incident management, Giva's platform covers the full ITSM picture, including:
Giva's products give IT teams the tools to classify, escalate, and resolve incidents with confidence.
Get a demo to see Giva's solutions in action, or start your own free, 30-day trial today!



Categories: IT, Help Desk