ITIL Problem Management Practice
ITIL Problem Management focuses on fire prevention, rather than firefighting. This article covers the essentials of Problem Management in IT.

Enlightened IT organizations have one thing in common: they focus on improving things — better alignment with the business, customer satisfaction, employee morale, reduced waste and costs, and more fun.
In most IT organizations, the one thing that stands in the way of greatness is recurring incidents and the constant firefighting effort to put out interruptions.
If this is your organization, this article is for you. It is about Problem Management and how it can make a difference in your organization.
The ITIL® Problem Management Practice is your answer to firefighting
The purpose of Problem Management
What is the main benefit of Problem Management in IT? The answer lies in its purpose, as defined by Axelos:1
"The purpose of the problem management practice is to reduce the likelihood and impact of incidents by identifying actual and potential causes of incidents and managing workarounds and known errors."
The objectives of Problem Management
What is the objective of Problem Management? IT Problem Management focuses on increasing the productivity of business users.2 It does this by:
- Preventing issues and subsequent incidents from occurring
- Eliminating repeat incidents
- Reducing the consequences of incidents that IT cannot avoid
Problem Management vs. Incident Management
Problem Management and Incident Management complement each other.
ITIL's definition of an incident is an:
"unplanned interruption to a service or reduction in the quality of a service."3
Incidents are harmful. Incidents keep users from being 100% productive. If users are less than 100% effective because the service is unavailable or not working right, they cannot get their jobs done, which means the business is losing revenue because of IT.
Incident Management is about getting the user back up and running as quickly as possible. Problem Management is not about getting them up and running quickly but about finding the root cause of the incident or interruption and fixing it so that it does not happen again.
The Problem Management Practice requires Incident Management to document incident records with extreme accuracy and consistency, particularly identifying the service impacted (i.e., from the Service Catalog), and the symptoms so that Problem Management can gather all similar incidents looking for the root cause. After doing this documentation, Incident Management links the incident to a problem.
Problem Management is crucial for optimizing IT service delivery. That is why ITIL provides links to other Practices and processes.
Problem Management inputs from other Practices
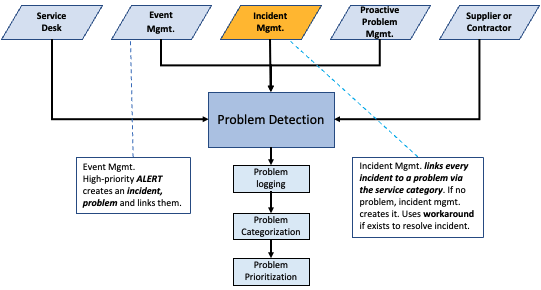
The business value of Problem Management4
- Lower incident frequency and duration, resulting in increased availability of IT services. The Problem, Incident, and Change Practices work together as a team to restore availability as quickly as possible.
- IT staff being more productive since incidents involve less unplanned work and may be resolved more quickly thanks to workarounds and known errors that have been logged.
- Spending less on workarounds and unsuccessful fixes.
- Lowering the cost of battling "fires" or stopping recurrent incidents. This is the most significant unnecessary cost in IT.
The Scope of the Problem Management Practice
Identification of problems is the first activity of Problem Management
Identification may happen in two ways: Reactive or Proactive Problem Management.
Reactive Problem Management
Reactive Problem Management responds to one or more incidents generated by Incident Management. This happens through an incident process called Incident Matching. We will discuss this in greater detail later. Problem Management identifies the problem when Incident Management creates the problem in the problem database and links the incident to an existing problem.
Proactive Problem Management
Proactive Problem Management includes locating and resolving issues and recognized errors before incidents recur. For example, suppose the desktop computer overheats because of a faulty fan. In this case, Proactive Problem Management will ask the question of Configuration Management, "How many other desktops do we have with the same type of fan?" Then they create an improvement project to replace all those fans preventing any further incidents and lost productivity.
Activities of Proactive Problem Management5
- Conducting major incident reviews. A major incident is one that has a large impact on company and necessitates an urgent, organized response.
- Conducting periodic scheduled reviews of operational logs (i.e., emergency changes) and maintenance records to look for potential problems.
- Organizing brainstorming sessions to find patterns that might point to underlying issues.
- Maintaining a close relationship with Continuous Improvement Practice and the Continuous Improvement Register (CIR).
Incident Matching is an important activity for the success of the Problem Management process
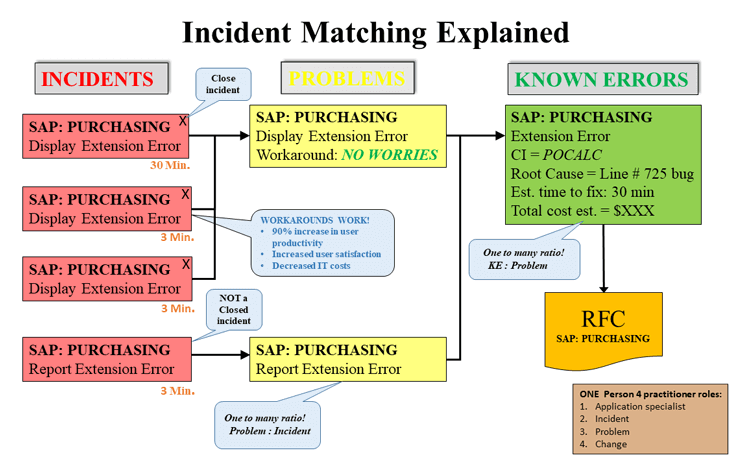
This diagram is the secret to Problem Management:
-
Three databases. Incident, Problem, and Known Error:
- Incident: Records of service interruptions.
- Problem: Records of the cause or potential cause of one or more incidents.
- Known Error: A problem that has undergone analysis but still requires fixing.
-
When the Service Desk agent, in the role of Incident Management, creates an incident:
- They document the incident starting with the service (SAP: Purchasing) from a dropdown menu of Service Catalog services.
- They enter a short description (i.e., the symptoms).
-
The Service Desk agent clicks the matching button on the screen to see if anyone has reported this before: No need to write, this is all automatic:
- Query Known Errors for open items with category "SAP: Purchasing" and anything close to extension error. If nothing is found, then
- Query Problem for open items with category "SAP: Purchasing" and anything close to extension error.
- If not found, auto-create a new problem record and link the incident to the problem. If found, link the incident to the problem.
- If Problem Management has a workaround, apply it and close the incident. A note about notifying the user of a workaround: Since we closed the incident, send a modified notice (i.e., "We have closed the incident by providing you with a workaround. While the incident is closed, the problem remains open."
100% of all incidents must be linked to a problem or Problem Management will not be successful
Everyone must follow the rule if Problem Management is to succeed. Accurate incident data is the key to success.
Problem logging is similar to incidents
No matter who logs a problem, it is much the same as with incidents. Regardless of the detection method, Problem Management requires a high degree of accuracy because they want to make it easy to find a match when doing Incident Matching.
The drop-down menu for the problem service category is the same as an incident. In fact, Incident, Problem, Known Error, Request, and Change are exactly the same drop-down menus. They must be under change control to ensure they stay in alignment. The categories represent the services offered to users, and they match what is in the Service Catalog.
Problem prioritization is similar to incidents
Problems should initially have the same priority as the incident that initiated the problem. For example, if the incident is Priority 3, then the problem is Priority 3. Problem Management may use Monitoring and Event Management Practice to create an escalation event. For example, if a problem has 3 incident matches as a 3 Priority, with the fourth matching incident, Event Management increases the problem priority by one and sends a notification to the associated service group ITIL Problem Manager of the change.
Workarounds are a gift from Problem Management
What defines a "workaround"?
"A solution that reduces or eliminates the impact of an incident or problem for which a full resolution is not yet available. Some workarounds reduce the likelihood of incidents."6
The diagram above also shows how Problem Management takes incident input and looks for other possible records. For example, Display Extension Error and Report Extension Error may have the same root cause.
The diagram demonstrates one person may act in different roles:
- The SAP Purchasing team programmer looked into the incident the first time and documented what they found. They had a workaround. They contacted the user to let them know the resolution. They played the role of Incident Management.
- The same programmer looks into the problem with linked incidents. The linking of several incidents gave them a clue to the root cause. Then, by adding another incident about the month-end report, they queried the Configuration Management System (CMS) for a Configuration Item (CI) that did the calculation for both the screen and the reports. They played the role of Problem Management.
- Once they found the programming error, they created a Request for Change (RFC) to Change Enablement, asking permission to change the live environment. They acted as a Change agent.
- Once tested and corrected, they documented the known error with notes about the fix, cost estimates, and suggestions for improvement. They acted in the role of Problem Management.
Without Incident Matching, Problem Management would take many more resources, take longer, and increase costs to IT and business users. In addition, because Problem Management staff document what they have found, workarounds, and other valuable information, Service Desk agents have the ability to assist users without escalation, also saving money.
Problem Management sample workflow7
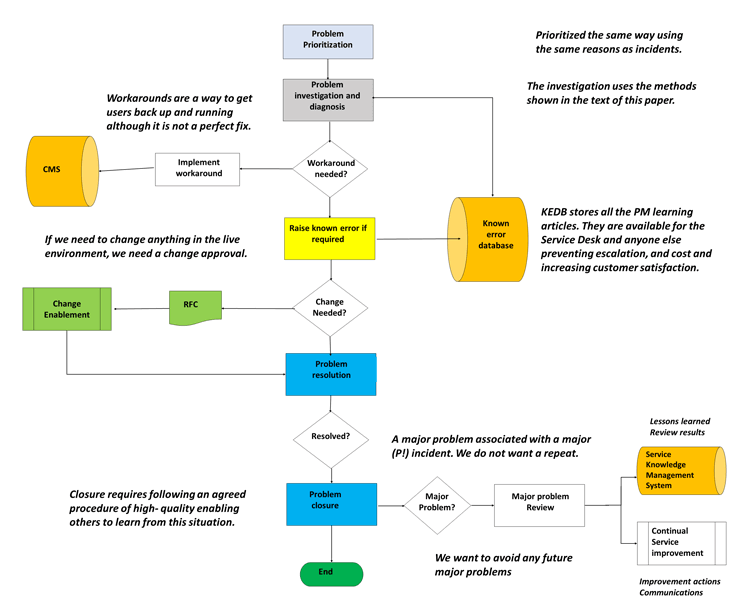
Problem Management analysis techniques
There are several techniques used by Problem Management staff to find the root cause. Each as different characteristics for different circumstances. Here is a brief overview:8
| Technique | Description |
|---|---|
| Chronological Analysis | Create a timeline of events by succinctly describing each event in the order that it occurred. This might demonstrate the initiating circumstance(s). |
| Pain Value Analysis | To identify the precise pain level, beginning with the worst. A more thorough examination is performed rather than counting the number of problems or incidents of a certain kind. |
| Kepner and Tregoe |
Look at the following stages for examining deeper issues:
|
| Brainstorming | Bring everyone who is relevant together and have a brainstorming session about the issue to discover potential causes and solutions. |
| 5 Whys | The 5-Whys is simple and effective. Describe the event that occurred first, then inquire as to "why this occurred," and finally, "why that occurred." Once you dig deeper down five times, you usually find the answer. |
| Fault Isolation | This method entails carefully re-running step by step the transaction or events that caused a problem, one Configuration Item (CI) at a time, until the problem CI is found. |
| Affinity Mapping | Using this method, a significant amount of information (ideas, opinions, issues) can be grouped together based on shared traits. Then under each grouping, look for potential causes. |
| Hypothesis Testing | Based on informed guesses, this technique can produce a list of potential root causes, which can then be used to test the veracity of each hypothesis. |
| Technical Observation Post | The TOP is suitable for intermittently recurring problems for unknown reasons or causes. This strategy involves bringing together professionals and technical support workers from the IT support organizations in advance to concentrate on a particular issue. |
| Ishikawa Diagrams | An approach of recording causes and consequences that can be helpful in figuring out where something might go wrong or how to improve it. These are sometimes called Fishbone Diagrams. |
| Pareto Analysis | This method is used to distinguish the most important probable failure causes from smaller problems. The Pareto Principle states that 80% of problems can be traced back to 20% of causes. The Pareto Analysis pinpoints the issues or tasks that have the greatest benefit. |
Staffing for Problem Management
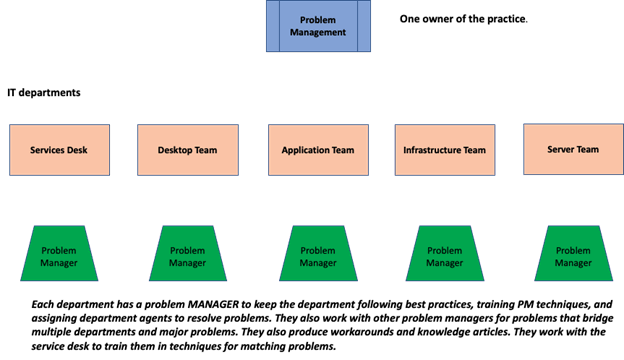
Staffing for any of the 34 ITIL Practices follows the same best-practice formula. Each Practice should have one owner responsible for the Practice. Owners set the rules of engagement. They continuously improve their Practice. They work with other Practices to collectively stay in alignment with the business.
Each IT department has a person assigned as a Practice Manager. Practice Managers make sure the department is in alignment with the Practice owner. They work with other Practice Managers, learning, coaching, and continually improving. You may want to rotate others into the role every quarter for "fresh eyes" and cross-training.
Problem Management benefits greatly if senior IT management sets Problem Management goals for all IT departments. For example, all IT departments should reduce recurring incidents for their department by 10% each quarter. Imagine how this would save manhours and costs for IT. Think of how much it would free resources for continuous improvement projects.
Problem Management triggers, inputs, outputs, and interfaces9
Problem Management triggers
- One or more incidents are the most common trigger for problem creation.
- Testing in the development stage may be a trigger, particularly User Acceptance Testing (UAT).
- Suppliers may trigger Problem Management as well with defects in their bug report that they failed to tell you about.
- Proactive Problem Management may see trends when reviewing historical incident data.
- Operation and event log patterns (i.e., Monitoring and Event Management) are other good sources for Proactive Problem Management.
Problem Management inputs
- Incident records
- Incident reports and histories
- Information about CIs
- Feedback and discussion of incidences and their characteristics
- Feedback and discussion of RFCs, releases, and deployments
- Event Management communication
- Established standards for prioritizing and escalating problems
- Risk Management output
Data quality begins with the Service Desk
- Resolved problems
- Updated records for Problem Management that have correct information and history
- RFCs to remove infrastructure errors
- Workarounds for incidents
- Known error records
- Problem Management reports
- Results and suggestions for improvement from significant problem analyses
Problem Management interfaces with other ITIL Practices
| Practice | Relationship |
|---|---|
| Financial Management |
Evaluating the effect of a suggested fix or workaround.
Estimating the cost of issues and their prevention.
|
| Availability Management |
Discovering how to improve uptime and decrease downtime.
Sending Availability Management problem analysis.
|
| Capacity & Performance Management |
Assistance from Performance Management teams and techniques when investigating performance problems.
Information on Problem Management that is relevant to good decisions.
|
| IT Service Continuity Management | Problem Management is the entry point into IT Service Continuity. When significant loss is probable if not resolved quickly, Problem Management works with ITSCM. |
| Service Level Management |
Problems and incidents are directly related, and this has an impact on how well services are delivered.
Enhancements in service levels are made possible via Problem Management.
SLM establishes constraints for Problem Management to operate within.
|
| Change Enablement |
Problem Management ensures that all changes and workarounds that require a change to a CI have an RFC.
When fixing changes that failed, Problem Management responds.
|
| Configuration Management | Problem uses the CMS to identify faulty CIs and to determine the impact of problems and resolutions. CMS CI relationships are essential for knowing how everything works together. |
| Knowledge Management | Service Knowledge Management System (SKMS) can hold the Known Error Database (KEDB) or integrate with the problem records. |
| Continuous Improvement | In order to find possibilities for service improvement and submit them to the Continuous Improvement Register (CIR), Problem Management uses incidents and problems. |
Problem Management Metrics: Critical Success Factors (CSF) and Key Performance Indicators (KPI) 10
-
CSF: Reduce the negative business effects of unavoidable incidents:
- KPI: The # of known errors added to the KEDB
- KPI: The % accuracy of the KEDB
- KPI: the % of incidents closed by the Service Desk without escalation because of the KEDB
-
CSF: Eliminate reoccurring incidents to maintain the quality of the IT services:
- KPI: Total number of problems (as a control measure)
- KPI: Size of current problem backlog for each IT service
- KPI: # of repeat incidents for each IT service
- KPI: % of recurring incidents for each IT department and trends
-
CSF: Make problem-solving efforts of high quality and professionalism:
- KPI: # of major problems
- KPI: The % of major problem reviews completed successfully and on time
- KPI: # and % of problems incorrectly assigned
- KPI: # and % problems incorrectly categorized
- KPI: Average cost per problem
- KPI: # and trend of duplicate problems
Takeaway: Problem Management is essential to ITIL
Every incident causes loss of user productivity in the business. This can lead to lost revenue. Every incident requires one or more IT staff to drop what they are doing to fix the incident. Fixing incidents should not be the job of the IT staff. The business wants IT to maximize the number of improvement projects to allow the business to become more competitive and successful. With staff fighting fires, something must give.
Enlightened IT organizations continually focus on value and eliminating waste. The Problem Management Practice is the Practice to get IT out of firefighting. Setting a BHAG (Big Harry Audacious Goal)11 of a 10% reduction in recurring incidents for each quarter for each IT department is exactly the ITIL Problem Management challenge you need to benefit the business and IT.
Footnotes:
- ITIL® Foundation ITIL 4 Edition, Axelos Global Best Practice, 2019, p.130
- ITIL 3, Service Operation, 2011 edition, Axelos, p. 97
- ITIL Service Operation, 2011 (ITIL 3) Edition, Axelos Global Best Practices, p. 157
- Ibid, ITIL 4, p. 121
- Ibid, ITIL 3, p. 98
- Ibid, ITIL 3, p. 99
- Ibid, ITIL 4, p. 132
- Ibid, ITIL 3, p. 102
- Ibid, ITIL 3, p. 106-107
- Ibid, ITIL 3, p. 99-101
- Ibid, ITIL 3, p. 109-110
- Jim Collins, Built to Last: Successful Habits of Visionary Companies, 2011

About the Author
Bart Barthold
Bart Barthold is an independent senior ITIL instructor with years of experience in combining ITIL knowledge with practical expertise in running a world-class support organization. He has earned the certificate for the highest level of ITIL training - IT Service Manager, holds an MBA, and he has taught various ITIL certifications and hundreds of students since 2004.
Bart is known for his outstanding performance in IT service management and is a recipient of the Help Desk Institute's prestigious Team Excellence Award in 1998. He also finished second in 1997, making him one of the most decorated IT service managers in the industry.