How IT Help Desk Teams Can Use AI to Manage Knowledge Articles Without Losing Accuracy or Compliance
 By Ron Avignone
By Ron Avignone
An IT technician closes a support ticket and, before moving on to the next one, an AI has already drafted a knowledge article from the resolution notes and queued it for review. That workflow is real, and it's spreading across ITSM platforms fast. But it's also where teams run into trouble.
AI knowledge management in IT help desks means using generative AI and machine learning to automate article creation, gap detection, and stale-content monitoring, while human review workflows and Retrieval Augmented Generation (RAG) enforce accuracy and compliance. Speed and accuracy aren't the same thing. An AI draft built from thin or incomplete notes, a stale article that slipped through a gap in the review process, a chatbot confidently citing an out-of-date procedure. Any of these can send a technician down the wrong path, or create compliance exposure in a regulated environment. This guide covers how IT help desk teams are building the governance structures, review workflows, and technical guardrails that make AI-assisted knowledge management reliable rather than just fast.

Key Takeaways
- AI generates, humans govern: AI drafts knowledge articles from resolved tickets and flags gaps automatically, but no AI-generated draft goes live without a human review stage.
- RAG keeps AI answers grounded: The most reliable teams use Retrieval Augmented Generation (RAG) to anchor chatbot answers to their approved internal knowledge base, preventing the model from drawing on general training data that may be outdated or wrong.
- Governance is harder than generation: Setting up an AI drafting tool takes days. Building the review workflows, confidence thresholds, audit logs, and content ownership rules that keep content accurate over time takes months. That gap is where most implementations stall.
- Compliance adds non-negotiable checkpoints: In regulated environments, HIPAA and SOC 2 require documented approval chains, audit trails, and access controls that go beyond typical quality review. These aren't optional extras.
- The next shift is Human-on-the-Loop: Leading teams are beginning to move from Human-in-the-Loop (humans approve before publishing) toward Human-on-the-Loop (AI acts, humans monitor and can override). That shift requires more mature governance, not less.
How AI Works Across the Knowledge Management Lifecycle
IT help desk teams are deploying AI across more of the knowledge management lifecycle than most people realize. The phases following are distinct in how they work and in the value each one delivers:
-
Gap Detection and Stale-Content Flagging
The most immediate value AI delivers is finding where your knowledge base is failing before your technicians tell you. AI systems can monitor unanswered self-service searches, ticket volumes by topic, and escalation rates per article. When users repeatedly search for something without finding a useful result, that's a signal a gap exists. When tickets open on a topic where an article already exists but gets low satisfaction scores, that signals the article isn't solving the problem.
Stale content detection works differently. AI compares the resolution steps from recent tickets against what existing articles describe. If technicians are consistently resolving a category of issue differently than the published article recommends, the system flags the article for review. This matters more than it sounds. For example, a VPN troubleshooting guide from two years ago can be completely accurate about the original setup and wrong about everything since the network was reconfigured.
-
Generative Article Drafting from Resolved Tickets
Once a ticket is closed, generative AI can convert the work log, resolution notes, and any attachments into a structured draft article. The technician doesn't start from a blank page, and the article captures the actual resolution rather than a sanitized summary written days later from memory. The quality of that draft depends directly on how well the technician documented the ticket. Vague closure notes produce vague articles, and AI can't compensate for notes that don't explain what the technician actually did. This is why the Knowledge-Centered Service (KCS) practice of documenting the fix at the moment of resolution matters so much. It's the input quality that makes everything downstream work. These raw inputs are unstructured data, and converting unstructured data into structured, searchable articles at scale is the core value AI drafting delivers in a knowledge management context.
HDI benchmarking finds that service desks with mature KCS practices have first contact resolution rates approximately 12 percentage points higher than those with no or immature KCS. The discipline of capturing resolutions at the moment of closure is what determines whether the AI has accurate source material to draft from.
When a technician closes a ticket, they document the fix as part of the closure process. Over time, the knowledge base reflects actual resolutions rather than idealized procedures. ITIL 4's Knowledge Management practice operates at a complementary level, focusing on the broader lifecycle of ensuring knowledge is accurate, accessible, and retired when it becomes obsolete. KCS and ITIL address the same goal from different directions, and teams that work within both frameworks tend to build more mature governance structures than those that rely on either alone.
AI doesn't replace KCS. It augments the steps KCS practitioners have always struggled with. These are the tasks that matter:
- Capturing a structured article from a rough resolution note
- Flagging existing articles when new ticket resolutions diverge from what they describe
- Identifying which articles need updating based on usage patterns and escalation rates
AI handles all of these at a scale and speed that's impossible to maintain manually. The KCS process provides the discipline, and AI provides the scale. What makes the combination work is a clear ownership model that defines who reviews AI-flagged updates and how quickly.
A 1up.ai survey of knowledge management practitioners found that 97% say human curation is still essential to AI-driven knowledge systems, even as automation handles more of the operational work. The humans are not being replaced. They're being freed from the capture and flagging tasks to focus on the judgment calls those tasks were previously crowding out.
-
Real-Time Agent Recommendations
The recommendations engine is the capability that most directly reduces Mean Time to Resolve (MTTR). When an agent opens a ticket, AI analyzes the description, category, and any prior context, then shows the agent relevant articles automatically without the agent needing to search. The difference from a keyword search is that AI reasons about the underlying problem, not just the words in the ticket.
New technicians benefit from this the most. A well-tuned recommendations engine effectively transfers institutional knowledge to someone in their first few weeks, showing them articles they wouldn't have known to search for. This is what ITSM practitioners mean when they talk about solving the "tribal knowledge" problem. Tribal knowledge is the accumulated expertise that experienced technicians carry in their heads and that rarely makes it into formal documentation until someone explicitly decides to write it down.
-
Continuous Content Health Monitoring
After articles are published, AI tracks per-article metrics:
- How often it's accessed
- What percentage of users found it helpful
- How frequently tickets in that category are escalated after consulting it
Some platforms generate a content health score for each article based on these signals. Drift detection though is the more interesting capability. When multiple recent tickets resolve a problem in a way that contradicts an existing article, the system flags the conflict rather than waiting for a scheduled review cycle or relying on a technician to notice the discrepancy. Every AI interaction feeds back into this monitoring layer, creating a continuous feedback loop between real-world ticket patterns and knowledge base quality.
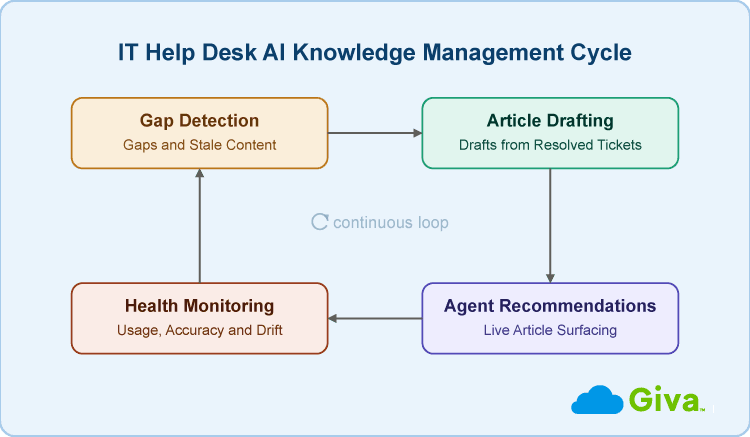
IT Help Desk AI Knowledge Management Lifecycle
5 Types of AI in Knowledge Management, Each With Different Governance Requirements
Before designing governance around any of these capabilities, it helps to classify what each type of AI is actually doing. Most platforms combine several of these, but each type carries different review requirements and different compliance implications:
- Content Generator: Creates draft articles from resolved ticket data, work logs, or existing documentation. Acts on a trigger (a closed ticket, a detected gap). Output is always a draft, never published directly.
- Knowledge Monitor: Scans the knowledge base continuously for stale, conflicting, duplicate, or low-performing articles. Flags items for human review rather than changing them autonomously.
- Retrieval Engine (RAG): Powers the AI chatbot or agent-assist feature. Pulls answers exclusively from the approved internal knowledge base rather than the model's general training data. This is the primary mechanism for preventing hallucinations at the point of answer delivery.
- Recommendations Engine: Shows relevant articles to agents in real time during active tickets. Operates passively without an agent initiating a search. Distinct from the Retrieval Engine, which responds to a direct question.
- Content Tagger: Applies AI-generated category labels and topic tags to articles at creation or update. In large knowledge bases, consistent taxonomy is difficult to maintain manually, and inconsistent tags degrade retrieval quality. Automated tagging removes this decision from the reviewer without reducing content review quality.
AI in Knowledge Management Summary Comparison
Type |
Primary Function |
Triggered By |
When Human Review Applies |
Compliance Relevance |
Content Generator |
Drafts new articles |
Closed ticket or detected gap |
Before any article goes live |
High: accuracy and approval trail required |
Knowledge Monitor |
Flags stale or conflicting articles |
Scheduled scan or real-time signal |
When reviewing flagged articles |
Medium: audit trail of review actions |
Retrieval Engine (RAG) |
Answers questions from approved KB |
User or agent query |
When confidence threshold is not met |
High: source attribution for regulated content |
Recommendations Engine |
Shows relevant articles to agents during tickets |
Active ticket opening |
Not typically required in real time |
Low to medium: depends on content sensitivity |
Content Tagger |
Applies AI-generated category and topic tags |
Article creation or update |
Not typically required in real time |
Low: supports retrieval quality, not a content accuracy control |
The Governance Workflow That Keeps Knowledge Base Accuracy Intact
AI drafting tools can be running in days. Building the review workflow, approval chain, versioning policy, and content retirement process to sustain that output is where teams spend their months.
Why Governance Is Harder Than Generation
Here's the failure point that shows up repeatedly. A team deploys an AI drafting tool, article volumes climb quickly, and the first 90 days feel like a win. Then the review queue starts backing up because no one's review responsibilities are formally defined. Articles sit in staging for two weeks. Some get published without meaningful review because the backlog pressure has built up. A year later, the knowledge base is larger but less trusted than it was before.
The failure mode is specific. A 40-person IT team enables AI drafting in their ITSM platform and triples their article count in 90 days. By month six, the review queue has 200 drafts, no reviewer owns any of them, and technicians have stopped consulting the KB because they no longer trust what they find. The AI performed as designed. The governance infrastructure wasn't ready.
The problem isn't the AI but that the team designed the generation step and assumed governance would work itself out. It doesn't. Governance requires the same explicit process design as any other operational workflow.
Human-in-the-Loop (HITL) Review: How It Works
Every AI-generated draft should enter a staging environment before publication. And the staging step can't be just a rubber stamp. It should be where a subject matter expert confirms technical accuracy, checks that the article aligns with current policy, and verifies it's written at the right scope.
Also, the review criteria should be written down and not assumed. Technical accuracy, policy alignment, appropriate scope, and readability are the four standard checks. For content that touches security procedures, compliance-sensitive processes, or anything a regulated industry considers a controlled document, a compliance check is a fifth checkpoint.
Teams should also define a review SLA, which would be the maximum number of days a draft can sit in staging before it either gets reviewed or expires and returns to the queue with a notification. Without that SLA, the staging environment becomes a graveyard for drafts no one feels urgency to complete.
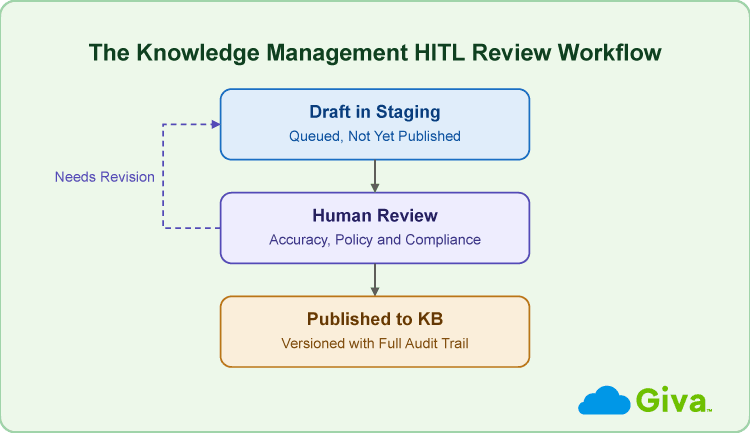
Knowledge Management HITL Review Workflow
Confidence Scoring and Escalation Thresholds
One of the least-discussed governance tools is confidence scoring. AI systems can compute how certain they are about an answer or a draft based on several signals:
- Retrieval quality: How closely the source material matches the question
- Source coverage: Whether multiple articles agree on the answer
- Intent clarity: How unambiguously the system understood the query
When confidence falls below a threshold, the system escalates rather than acting. For AI answer delivery, published benchmarks suggest escalating to a human reviewer when confidence falls below 60%. A confident response that's wrong is worse than an honest 'I'm not sure' that routes to a human.
Teams should set their own thresholds based on context. A knowledge base serving a healthcare IT environment where incorrect guidance could affect patient data handling warrants a higher threshold than one used for general IT how-to guides. And so, the threshold isn't universal but a risk management decision.
Version Control and Change Logs
Every article should carry a full edit history, capturing who changed it, what changed, when, and whether the change was AI-initiated or human-initiated. Rollback capability matters when errors are discovered after publication, which they will be.
In a regulated environment, the change log is critical because it's the audit trail that shows governance is working. If an article was published without a required review, the change log shows it. If an article was modified after approval without going back through review, the log shows that too.
Compliance Requirements in AI Knowledge Management
Much of the information about AI knowledge management treats compliance as a line item at the bottom of a feature list. For IT teams in healthcare, financial services, or any other regulated industry, it belongs at the top of the architecture conversation.
For IT help desk operations specifically, the knowledge base is the operational record your technicians work from. In a regulated environment, that makes every knowledge article a potential audit artifact, not just a reference document.
Why the Compliance Stakes Are Higher Than You Think
In a regulated environment, an inaccurate AI-generated knowledge article isn't just a quality problem. If a healthcare IT help desk publishes AI-generated guidance that incorrectly describes how to handle a system containing patient health information, and a technician follows it, that's a potential HIPAA violation.
And the organization doesn't get to point at the AI vendor. The obligation is on the organization to have controls in place that prevent inaccurate guidance from reaching practitioners.
What HIPAA-Regulated IT Help Desks Need to Know
HIPAA compliance requirements touch knowledge management in two specific ways:
- First, any knowledge article that describes procedures for handling Protected Health Information (PHI), including policy documents covering access control configurations, breach notification steps, or data retention procedures, is a controlled document. It needs to go through a compliance review checkpoint, not just a technical accuracy review.
- Second, the AI vendor itself needs to be in scope. If the AI drafting tool processes or stores knowledge base content that might include PHI (even as context), the vendor must sign a Business Associate Agreement (BAA). And many general-purpose AI tools don't offer BAAs. Choosing a platform that does then, or that is purpose-built for HIPAA environments, is imperative for healthcare organizations.
SOC 2 and Documented Approval Chains
SOC 2 Type II certification requires organizations to show that their operational processes include documented controls. For AI knowledge management, this means auditors will want to see:
- A documented approval workflow
- Access control logs showing who can create, edit, and approve articles
- A change history for published content
ISO 42001, the AI management system standard published in 2023, is becoming relevant for organizations that need to show responsible AI governance to regulators or enterprise customers. It covers how AI systems are designed, deployed, monitored, and controlled. Teams in industries where AI governance is increasingly scrutinized would do well to track it.
Internal vs. External Knowledge: Different Risk Profiles
Agent-facing knowledge used during ticket resolution by trained IT staff carries a lower compliance risk than customer-facing self-service knowledge used by end users who may lack context to apply it correctly. A chatbot that gives a healthcare employee inaccurate guidance about PHI handling is a higher-risk failure than an IT agent reading the same article and applying their own professional judgment.
The practical implication is that the governance structure should reflect the audience, not just the content. External self-service knowledge bases and customer-facing chatbots should have stricter review checkpoints than internal agent-assist content. Many teams apply the same governance standards across the board, which either over-burdens the internal workflow or under-protects the external one.
Knowledge Type |
Audience |
Compliance Risk Level |
Review Checkpoint Required |
Key Concern |
Internal Agent Assist |
Trained IT staff |
Medium |
Technical + policy accuracy |
Outdated procedures, conflicting guidance |
External Self-Service |
End users (employees) |
High |
Technical + policy + readability |
Misapplication by non-technical users |
Customer-Facing Chatbot |
External customers |
Highest |
All checkpoints + compliance review |
Regulatory exposure, brand liability |
RAG: The Architecture That Keeps AI Grounded
Retrieval Augmented Generation (RAG) is the architecture that grounds AI chatbot answers in your organization's approved knowledge base rather than the model's general training data. It's the primary technical mechanism for keeping answers accurate and auditable, and it's the one architectural decision that most directly affects compliance in regulated environments.
For IT help desk teams, the difference between a plausible general answer and the correct answer for your specific environment is where incidents start. RAG narrows that gap by pulling responses from your maintained KB rather than from training data that knows nothing about your infrastructure.
How RAG Reduces Hallucinations
In a standard large language model without RAG, the AI generates answers from its training data, which may be outdated, incomplete, or simply wrong for your specific environment. With RAG, when a user or agent asks a question, the system first retrieves relevant passages from your internal knowledge base, then generates its answer grounded in those specific passages. The model can only say what the retrieved documents support.
This reduces hallucinations significantly but doesn't eliminate them entirely. If the retrieved document is itself inaccurate or outdated, the AI's answer will reflect that. This is why the quality of the knowledge base matters as much as the architecture. RAG is a control, and it doesn't substitute for governance.
Source Attribution as an Audit Trail
A well-implemented RAG system cites which knowledge base article it pulled from to generate each answer. That source citation creates a traceable chain from the AI's response back to the approved document it was based on.
For compliance purposes, this trail is valuable in both directions. If a technician followed AI-generated guidance and something went wrong, the audit trail shows which article the AI cited, when that article was approved, and who approved it. If the article was accurate at the time and later became outdated without being updated, the change log shows that gap. The source attribution turns every AI interaction into a documented, auditable event.
Access-Controlled Knowledge Categories
In most ITSM platforms, the knowledge base can be segmented by audience or permission level, and RAG can be configured to pull only from the category the requesting user is authorized to access. A contractor sees different articles than a full-time employee. A Tier 1 technician may not have access to the same security configuration procedures as a senior engineer. In healthcare, this prevents AI from citing PHI-handling procedures for users who aren't cleared to work with that data.
Where AI Knowledge Management Is Heading
Most IT teams deploying AI knowledge management today are doing it in ways that were considered advanced just two years ago. The field is moving fast, and understanding where it's going helps teams design governance structures that won't need to be rebuilt in 18 months.
From Human-in-the-Loop to Human-on-the-Loop
Human-in-the-Loop (HITL) means a human approves every AI action before it takes effect. Every AI draft goes through review before publishing. Every AI answer to a high-stakes question routes to a human before being sent. This is the standard approach today, and for most organizations it's the right starting point.
Human-on-the-Loop (HOTL) is the direction mature programs are moving, where AI acts autonomously and humans monitor outcomes with the ability to intervene or roll back. For knowledge management, this might mean AI publishes low-stakes updates automatically (a phone number change, a screenshot update) and flags high-stakes revisions for human review.
HOTL isn't a relaxation of governance. It requires more sophisticated monitoring, faster rollback capability, and clearer categorization of what counts as low-stakes versus high-stakes content. There's no consensus benchmark for when a team is ready for HOTL. It depends on how mature the monitoring and rollback systems are, not how long the team has been using AI. Teams that try to move to HOTL without that infrastructure in place tend to discover the gaps when something goes wrong at scale.
|
HITL (Human-in-the-Loop) |
HOTL (Human-on-the-Loop) |
How it Works |
Human approves each AI action before it takes effect |
AI acts autonomously; humans monitor outcomes and can roll back |
Knowledge Management Example |
AI drafts article; human reviews; publishes only after approval |
AI publishes low-stakes updates automatically; flags high-stakes for human review |
Governance Requirement |
Review workflow, staging environment, SLA, named reviewers |
Monitoring infrastructure, rollback capability, risk classification by content type |
Common Failure Mode |
Review backlog when ownership and SLAs are not defined |
Moving to HOTL before monitoring and rollback systems are proven |
Right For |
Most IT help desk teams today |
Teams with mature governance and proven monitoring infrastructure |
Agentic Knowledge Bases: The Self-Maintaining Model
Agentic AI refers to AI systems capable of taking autonomous, multi-step actions without human direction for each step. Applied to knowledge management, an agentic model closes the full loop from ticket resolution to article drafting to review routing to publication to ongoing monitoring and update flagging. The knowledge base becomes a system that maintains itself rather than a library requiring constant manual curation.
This is forward-looking rather than current. Most organizations still have humans initiating each step manually or semi-manually. The technical capability exists in current-era platforms, but the governance infrastructure to support fully autonomous maintenance is not widely deployed yet. Teams considering agentic knowledge management should plan the governance architecture first. That means defining what gets auto-published, what requires a human checkpoint, and what happens when the agentic loop produces a conflict between two articles it has both modified.
6 AI Knowledge Management Pitfalls IT Help Desk Teams Hit First
Teams that get AI knowledge management right have almost all hit at least one of these first:
- Auto-publish off by default: Publishing AI-generated content without review.
Even a single inaccurate article that circulates widely before being corrected can erode technician trust in the entire knowledge base. Once people stop trusting the KB, they stop consulting it, and the value of the investment disappears. Turn auto-publish off. Build the review workflow first.
- Assign every article an owner: No explicit content ownership.
When ownership is undefined, articles accumulate flags that no one reviews, and stale content persists indefinitely. Every article should have a named owner who is accountable for its accuracy and for responding to AI-generated update flags within a defined timeframe.
- Process first, platform second: Treating AI knowledge management as a technology project rather than a process redesign.
The platform is roughly 20% of the work. The other 80% is the review workflows, approval SLAs, reviewer training, and governance policies. Organizations that buy a tool and expect it to create the process find out otherwise around month three.
- Map your regulatory obligations before deployment: Ignoring compliance requirements for your industry.
Healthcare and financial services organizations that deploy AI knowledge management without addressing HIPAA, SOC 2, or applicable regulations are creating liability rather than solving problems. Compliance requirements should shape the architecture and not be retrofitted after the fact.
- Measure quality, not just volume: Optimizing only for speed.
Articles created per month is a vanity metric for knowledge management. The measures that matter are:
- Accuracy rate: How often AI-drafted articles are approved without major revisions
- Escalation rate: How often AI answers are flagged by users as wrong or unhelpful
- Article health score: What percentage of the knowledge base is within its review cycle and marked accurate
- Ticket deflection rate: How often the self-service knowledge base resolves issues without a ticket being opened
- FCR (First Contact Resolution) trend: Whether resolution rates improve as the knowledge base grows and stays current
- Address the human side of the deployment: Underestimating adoption resistance.
A lack of AI literacy and technician trust in AI-generated content is one of the most common silent failure areas. If technicians don't trust the knowledge base, they stop consulting it, regardless of how accurate it is. Structured onboarding for the AI tools, clear communication about how articles are reviewed before publication, and visible examples of AI flagging and correcting outdated content all contribute to building that trust. Adoption is a process design problem, not a communication one. Build the training and feedback loops into the deployment plan from the start.
FAQs: AI Knowledge Management in IT Help Desks
-
What is human-in-the-loop in AI knowledge management?
Human-in-the-Loop (HITL) in knowledge management means that every AI-generated draft or AI-initiated change requires human approval before it takes effect.
The workflow typically looks like this. AI drafts an article and routes it to a staging environment. A subject matter expert reviews it for technical accuracy, policy alignment, and appropriate scope. Only after approval does the article publish to the live knowledge base. The AI is an author's assistant, not an autonomous publisher.
HITL is contrasted with Human-on-the-Loop (HOTL), where AI can act autonomously and humans monitor outcomes with the ability to roll back changes. HOTL is appropriate for lower-stakes updates and for teams with mature monitoring and rollback capabilities. Most IT help desk teams are in HITL mode today, which is the right starting point before scaling toward greater autonomy.
One practical detail that teams often skip is the review SLA. Without a defined maximum number of days a draft can sit in staging, articles queue up indefinitely and the governance process quietly collapses. A 48- to 72-hour target is a common starting point for most organizations.
-
How does RAG prevent hallucinations in a knowledge base?
Retrieval Augmented Generation (RAG) prevents hallucinations by constraining the AI to generate answers only from content it has retrieved from your internal knowledge base, rather than from its general training data.
When a user asks an AI-powered chatbot a question, a RAG system first searches the knowledge base for relevant passages, then generates its answer based on those passages. The model can't invent facts that aren't in the retrieved documents. The result is an answer grounded in your approved, maintained content rather than whatever the model learned from the broader internet.
The important caveat is that RAG reduces hallucinations but doesn't eliminate them. If the retrieved document is itself inaccurate or outdated, the AI's answer will reflect that. This is why the quality of the knowledge base matters as much as the architecture. RAG is a control but not a guarantee of accuracy.
-
Does HIPAA apply to AI-generated knowledge articles in healthcare IT?
Yes, HIPAA compliance applies to AI knowledge management in healthcare IT in two specific ways: the content of the articles and the AI vendor that handles them.
On the content side, any knowledge article describing procedures that involve Protected Health Information (PHI), such as access controls, breach notification steps, or data retention policies, is a controlled document under HIPAA. It needs a compliance review checkpoint before publication, not just a technical accuracy check. Publishing AI-generated guidance on PHI-handling procedures without a compliance review is the risk.
On the vendor side, if the AI drafting or knowledge management tool processes or stores content that might include PHI (even as part of ticket notes used to generate drafts), the vendor must sign a Business Associate Agreement (BAA) with your organization. A platform without a BAA option is not deployable in a HIPAA-covered environment regardless of its features.
-
How do IT teams detect stale knowledge articles automatically?
AI detects stale knowledge articles by monitoring three signals: usage patterns, ticket resolution data, and explicit user feedback.
Usage monitoring flags articles that haven't been accessed in a defined period (commonly 90 to 180 days, depending on article type). Ticket resolution data is more precise. When technicians consistently resolve a category of issue using steps that differ from what an existing article describes, the AI flags the article as potentially outdated. User feedback, including satisfaction ratings on self-service articles and escalation rates after AI recommendations, rounds out the picture.
Most teams run quarterly or semi-annual reviews as a second pass. Automated detection handles active content drift but won't always catch articles that have quietly become irrelevant to how the environment works. Scheduled review catches what automated detection misses.
One practical consideration worth calling out: AI-based stale detection is only as useful as the downstream process. If flagged articles sit unreviewed for weeks because there's no assigned owner or no SLA, the detection mechanism doesn't help. Stale content detection and content ownership are two parts of the same governance question.
-
What is the difference between agent-facing and self-service AI knowledge management?
Agent-facing knowledge is used by trained IT staff during ticket resolution; self-service knowledge is used directly by end users without a technician intermediary, and the difference in audience creates a significant difference in compliance risk and review requirements.
An IT agent reading a knowledge article applies professional judgment. They can recognize when something looks off, escalate, or cross-check before acting. An end user following a chatbot's AI-generated guidance on a password policy, a data handling procedure, or a security setting doesn't have that backstop. The guidance they receive is the guidance they follow.
The practical implication is that external self-service knowledge and customer-facing chatbot content should go through stricter review checkpoints than internal agent-assist content, even if the underlying articles cover similar topics. Many organizations apply the same governance standards across both, which creates either unnecessary burden on the internal workflow or insufficient protection on the external one. The governance structure should reflect the audience, not just the content.
Related Giva Resources
- Help Desk AI: Fully Examined + Effective Use Cases and How-Tos
- Knowledge Management Process: Best-Practices How-To Guide
- HIPAA-Compliant Help Desk Software
- Knowledge Management Best Practices, Tools, and KM Features
AI Knowledge Management in IT Help Desks: Generation Is the Easy Part
The teams that get the most out of AI knowledge management are the ones that understand what the technology is actually solving. AI is genuinely good at drafting, detecting gaps, recommending, and monitoring at a scale no team can match manually. Reviewing, approving, versioning, and governing that content over time is where the real work is, and it requires explicit process design, clear ownership, and governance structures that match the compliance environment you operate in.
The forward-looking picture is worth noting. HITL governance evolves toward HOTL as teams build the monitoring and rollback capability to support it. Agentic knowledge bases will handle more of the maintenance loop autonomously. KCS + AI will make continuous improvement the default rather than the exception. None of that replaces the judgment calls humans make in the review process but frees them to make those calls on what actually matters rather than on volume.
Start with governance. Design the review workflow before deploying the drafting tool. Name the owners, set the SLAs, build the audit trail. Then add the AI capabilities on top of a process that can actually sustain them.
Manage Knowledge Articles with AI and the Governance to Back It Up
AI-assisted knowledge management is only as reliable as the governance structure behind it. Getting the drafting and gap detection right is valuable, and making sure those drafts are reviewed, versioned, compliant, and accurate is what determines whether your help desk team can actually trust what it finds.
Giva's Help Desk Software and ITSM Software include integrated Knowledge Management with an AI Knowledge Copilot that brings relevant articles to agents in real time, RAG retrieval grounded in your own KB data so every answer cites the specific article it came from, HIPAA compliance at no extra cost, and up/down voting to give your team ongoing quality signals on article accuracy. For IT teams in healthcare, financial services, or any regulated environment, that combination is the difference between a knowledge management deployment that satisfies auditors and one that creates new compliance exposure.
The governance layer, including review workflows, approval SLAs, and content ownership structure, is a process your team designs. Giva provides the compliant, AI-enabled knowledge base infrastructure to build it on, including role-based access to knowledge.
Get a demo to see Giva's solutions in action, or start your own free, 30-day trial today!



Categories: IT, Help Desk