ITIL Incident Management Best Practices
Managing incidents correctly are critical to a successful IT organization. Learn ITIL Incident Management best practices & why they are so important

Incident Management has been a pivotal ITIL Practice since its inception in the late 1980s. In fact, in the same breath that we speak of the Information Technology (IT) department, we think "IT-to-the-rescue" when things don't work the way they should. This article looks in depth at the ITIL Incident Management best practices to demonstrate how to maximize value.
Overview of ITIL and the IT Incident Management Practice
What is the purpose of the Incident Management Practice?
The purpose is to minimize the negative impact of incidents by restoring normal service operations as quickly as possible.1
What is the definition of an Incident in ITIL?
An Incident is an unplanned interruption to service or a reduction in the quality of a service.2
Service Level Agreements (SLAs) define what normal service operations are.
From this simple definition, we infer that a user with an Incident cannot do their prescribed job. Therefore, the negative impact is what ITIL refers to as "lost productivity or revenue". Thus, any Incident harms the business.
From the IT perspective, Incidents mean firefighting and requiring IT staff to stop doing Continuous Improvement projects to respond quickly to get users back up and productive again. Firefighting is the primary cause of IT not keeping up with business demands for new and changed services.
Another fundamental Incident concept not well understood is the cause of Incidents in the first place. Most, if not all, Incident root causes stem from poor quality assurance of services from the Service Design Practice. Not embracing a zero-defects strategy leads to:
- Incidents
- Lost user productivity
- Increased IT demand
- Low business efficiency
All this is a high, unnecessary company expense.
The difference between Incidents and Service Requests
Because the Service Desk Practice handles Incidents and Requests, it can be confusing. Above, we learned that an Incident is a broken service (e.g. we are not delivering the service as per the SLA). A Service Request is everything else (i.e. not broken).
A simple, frequent example demonstrates the difference. A user cannot log in because they incorrectly entered their password. Nothing is wrong. Our security policy worked as designed. From the user's perspective, the login failed (i.e. Incident). From an ITIL perspective, it is a Request. The Service Desk should still get them back up immediately (i.e. a high-priority request) to increase user productivity.
The Service Desk is essential for the Incident Management Practice
The purpose of the Service Desk Practice:
To provide a clear path for users to report issues, queries, and requests and have them acknowledged, classified, owned, and actioned.3
The above word "issues" are Incidents. The Service Desk provides the best value when it acts as a Single Point of Contact (SPOC) for all IT. A best practice for all service SLAs is to state that the terms and conditions of the SLA are predicated on users contacting only the Service Desk. One of the Service Desk's responsibilities is Incident Management.
ITIL Incident Management and Ticketing
A simplified ITIL Incident Value Stream follows:
What is a Value Stream?
A Value Stream is a series of steps an organization undertakes to create and deliver consumer products and services.4
For example, the diagram of Incident workflow is a Value Stream. It defines the activities, workflow, controls, and procedures needed to achieve agreed objectives. Each step takes input from the previous step and applies documented processes to create a new value output for the next step.
ITIL 3 called Incident Management a "Process". That changed with ITIL 4, which we call Incident Management Practice.
A Process is a set of interrelated or interacting activities that transform inputs into outputs. A Process takes one or more defined inputs and turns them into defined outputs. Processes define the sequence of actions and their dependencies.5
Organizations should examine their work performance and map all the value streams they can identify in Incident Management. The analysis gives them the current state or how they perform work now. When analyzing the current state, they can identify barriers to workflow and non-value-add activities (i.e. waste). Eliminate waste to increase productivity: save money and increase customer satisfaction.
The role of the Service Desk in Incident Management
Single Point of Contact Portals
Before we look at the Incident Management workflow, we should understand that the Service Desk is responsible for most Incident Management tasks.
An efficient Service Desk manages many portals for users to report Incidents and Service Requests:
- Web interface
- Phone
- Chat
- Monitoring and Event Management (e.g. exception events automatically create a Prioirty-1 incident)
The Service Desk (Level 1 support) is the only way the IT organization should allow users to contact IT. If you do not enforce this rule, you cause a significant increase in service costs.
- Level 1 is the least expensive of all the IT levels.
- The Service Desk is the expert at incident management, customer support, and escalation.
- When the Service Desk resolves the Incident, the customer has less productivity loss, reducing costs and increasing customer satisfaction.
- Level 2 and 3 responsibilities are primarily Continuous Improvement projects; all escalation disruptions cause project delays and increased costs.
- When IT does not enforce SPOC by allowing users to go directly to Levels 2 and 3:
- The user jumps ahead of those in the queue (i.e. not fair),
- It increases project management time-to-market (i.e. more costs)
- It increases incident resolution time for most Incidents
- It increases disruptions, productivity loss, and costs
The efficient Incident Management workflow
Incident identification6
The Service Desk must log 100% of all Incidents for real, true demand impact. In addition, every logging step must be 100% correct because Problem Management Practice depends on it.
Incident logging7
The Service Desk opens a new Incident and begins to enter all required information.
Incident categorization
Entering the right category is essential for linking the Incident to Problems. The category is a dropdown menu representing all the services in the Service Catalog.
It is important to note that other Practices use this same dropdown menu. That is how they stay in sync:
- Incident Management
- Service Request Management
- Problem Management - Problem Database
- Problem Management - Know Error Database (KEDB)
- Change Enablement
Remember, our purpose is for Service Management to provide the organization with the highest level of service support. To do that effectively, we must have accurate data for each service.
Each Incident has several fields for categorization. ITIL defines two options and best practices for Incident categorization:
- Location > Service impacted > System impacted > Application impacted
- Application impacted > Database impacted > Server impacted > Disk drive impacted
Incident matching to a Problem8
After the Service Desk agent categorizes the Incident, along with a short description of the symptoms, the next step is to investigate whether anyone has experienced it before.
Most ITIL tools allow you to click a screen button to query the Problem Management databases: Problems, and Known Errors. The query is highly efficient as Problem Management keeps a close eye on the quality and efficiency of their databases, and they are significantly smaller.
A Problem is a cause, or potential cause, of one or more Incidents.
A Known Error is a Problem that has been analyzed but not resolved (i.e. investigation notes).
The query goes something like this:
- Show me any not-closed known errors with the same category + any variations of the short description. If we don't find one, then,
- Show me any not-closed Problems with the same category + any variations of the short description.
- If no matches, create a new Problem with the same category + the short description and digitally link the Incident to it.
- If the Problem exists, link the Incident to the existing Problem.
A benefit of linking to an existing Problem is a workaround9:
It yields a solution that reduces or eliminates the impact of an Incident or Problem for which a full resolution is not yet available.
If the workaround fits the situation, close the Incident. A good example is when the Service Desk tells the user to reboot. It allows the user to be productive again. Be sure to tell the user that IT is closing the Incident, but the Problem is still open, and we will work on it.
Incident prioritization
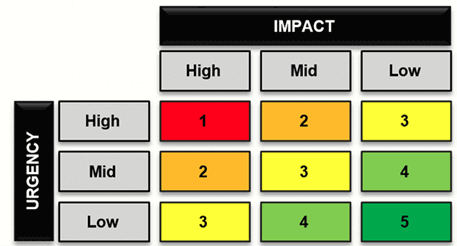
Another task the Service Desk is the most qualified for is setting Incident priority. To do this, and after a conversation with the user, the Service Desk agent determines the priority based on the following two criteria:
- The Urgency (e.g. how quickly the business needs the Incident resolved) and
- The Impact (i.e. to the business or department)
ITIL suggests that all IT departments create a simple priority coding system (see below).
When the IT organization links the Priority Matrix10 to the target resolution time, it is a good tool for accurately resolving incidents based on the priority level.
What is Incident Escalation?11
Initial diagnosis
The initial diagnosis is the job of the Service Desk. With this diagnosis, they are hoping to:
- Find a way to resolve this at the Services Desk, or
- Provide more documentation to Levels 2 and 3 support.12
If they find a way to resolve the issue and close, they do.
There are times when the Service Desk must escalate the Incident. The Incident Management Owner sets these times as part of the Practice strategy. Typically, it happens when more experience is needed to resolve the Incident and Level 1 escalates to Level 2 or 3.
It is important to remember that ITIL's best practice states that the Service Desk owns the Incident even when it escalates13. The reason for this policy is customer service. The bond between the user and the Service Desk agent and what the user knows is vital. The Service Desk agent still owns the Incident even though resolution responsibility shifts.
Two types of escalations14
-
Functional escalation: Assigning the Incident from Level 1 (Service Desk) to Level 2 or 3:
- The rules for when to do this are part of the Incident Management Practice strategy.
- SLA targets for the assigned priority are the trigger.
- Operational Level Agreements (OLAs) between the Service Desk and the group escalated to guide all escalations.
-
Hierarchical escalation:
- If Incidents are severe (i.e. high priority), best practice says to notify the appropriate managers.
- The Practice Owner documents the escalation process.
Major Incident Management process
Major Incidents (Priority 1) are a particular type of escalation.15 IT defines major (Priority 1) Incidents, escalation details, responsibilities, and timeframes. Speed and expertise are essential.
ITIL suggests that all escalation rules and handling of Incidents, in general, should be documented in the OLAs, which describes how the internal IT departments will work together under various circumstances. They are an essential part of best practices in Service Management.
Resolution identified?
Either the Service Desk resolves the Incident, or it is through escalation. The goal is to resolve and get users productive again.
Incident closure16
If Level 2 or 3 resolves the ticket, they complete all the documentation and send it back to the Service Desk for closure.
Incident Management and the importance of the Incident Audit17
No other IT database is as important as the Incident database. Every activity that IT undertakes has its origin in an Incident. What are you doing to ensure that the data in the database is perfect?
We brought attention to the fact that all Incidents interrupt user productivity and, therefore, bring loss of revenue. Not only that, other ITIL Practices rely on Incident information. For example:
- Problem Management: Without accurate Incidents linked to Problems, you have no hope of finding root causes to eliminate recurring Incidents and significantly improve productivity and save money.
- Continuous Improvement: Improving alignment with business needs requires the knowledge of discordance. For a business to succeed, it takes everyone to contribute. Incidents only get in the way of this goal.
- Project Management: This Practice is all about improvements. Projects cannot deliver their potential value without accurate knowledge of infrastructure flaws (i.e. Incidents).
- Service Management: The role of Service Management is to optimize service delivery. Service owners cannot fulfill this role if they do not have accurate Incident information for the Service they own.
- Warranty Practices: Practice owners for service warranty (Availability, Capacity, Security, and Continuity) depend on accurate Incidents to tell them when their service is not delivering value.
- Service Configuration Management: This Practice responsibility is accurate Configuration Items (CIs) and their relationships. Since they link Incidents to the CIs causing the Incident, inaccurate Incidents compromise the effectiveness of the Configuration Management System (CMS).
Audit throughout the Incident lifecycle18
Frequent audits along the Incident Value Stream are an easy way to provide a precise, accurate Incident record at the end.
- Each IT department creates an audit procedure and audit form.
- They audit the Incident before it goes to another team. The rules and how to execute they document in the OLA.
- The goal is zero defects. All Incidents must meet these high standards.
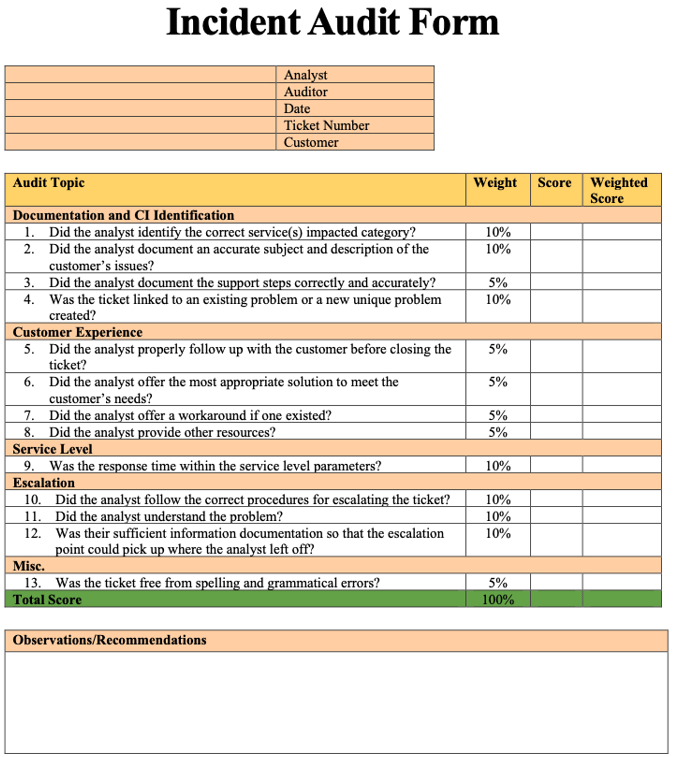
The Service Desk performs the final audit. They ensure the Incident passes a strict audit to meet the highest data quality for all ITIL Practices.
Example audit form for Service Desk incident quality
ITIL roles and responsibilities and using RACI
ITIL often speaks about accountability and roles. At the core of everything, ITIL is defining roles and responsibilities.
Practice roles and the RACI model19
For years, ITIL supported the RACI model to ensure all the ITIL roles know who does what.
RACI: Responsible, Accountable, Consulted, Informed
-
Responsible:
- People or stakeholders who do the work.
- They must complete the task or objective or make the decision.
- Several people can be jointly responsible.
-
Accountable:
- Person or stakeholder who is the "owner" of the work.
- A group cannot be accountable, only a single person (i.e. the buck stops here).
- The person to sign off or approve the completed task, objective, or decision.
- This person makes/verifies the assignment of responsibilities in the matrix for all related activities.
- Only one person is accountable!
-
Consulted:
- The people or stakeholders who require input before the work can start.
- These people are "in the loop" and are active participants.
-
Informed:
- People or stakeholders must be kept "in the loop" to promote visibility.
- They need updates on progress or decisions but are not formally consulted.
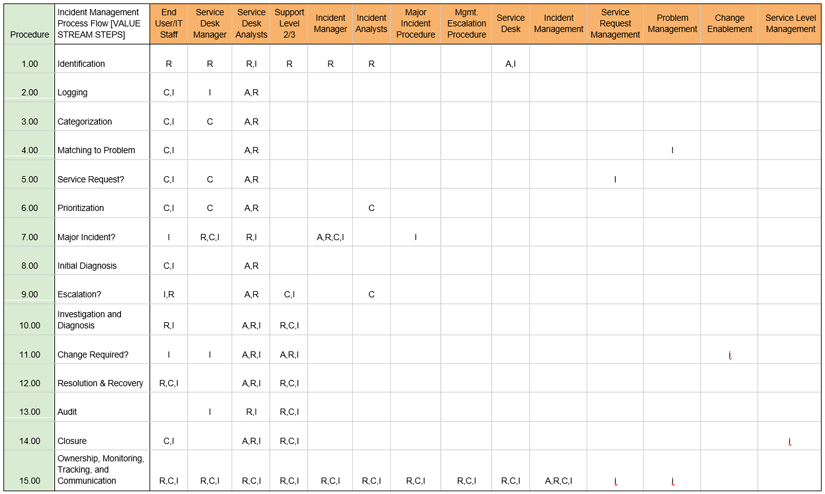
Who does what in the Incident Management Practice?20
The responsibility matrix below puts it all together.
Column 1: The documentation number for the processes for completing the task.
Column 2: The task's name or step in the Value Stream for Incident Management.
Columns 3-14: These roles participate in Incident Management Practice.
Looking at each position, you see the RACI model at the intersection between the Value Stream step and the position.
The matrix works because Operational Level Agreements (OLA) describe these relationships. All parties sign and agree on the OLAs. Every quarter, the staff in the different departments review the OLAs and RACI to find out what is working and what needs to be improved.
ITIL metrics for Incident Management
Creating a sense of urgency by measuring lost user productivity
It is common for Incident Management to report the number of Incidents for a designated period. The Severity Code usually reports these. These could be hundreds to thousands of Incidents. However, this is not what is essential, nor does it reflect the true cost of Incidents. There is a better way that measures the loss of user productivity.
Template for calculating the opportunity cost of Incident Management
The following is an example:
-
Step 1: Determine employee productivity
Annual employee productivity = Annual Revenue / # of EmployeesAnnual Revenue:$1,580,000,000# of Employees:1784Contribution each employee makes to annual revenue:$885,650Revenue/hour = Annual employee productivity per year/2080 hour/year:$426
-
Step 2: Estimate impact of incidents on employees
Incident Priority Estimated # Employees Impacted Mean Time to Restore (MTTR) Actual Impact on Productivity # Incidents Per Year Total Person Hours 1 500 1 1 40 20,000 2 200 4 2 200 80,000 3 30 8 4 2000 240,000 4 1 24 4 12,000 48,000 Total: 388,000 Person hours of productivity lost due to incidents:$388,000Person years (Person hours/2080):187 -
Step 3: Calculate the cost of incidents on productivity
From Step 1, the Annual revenue generated by one person:$885,650From Step 2, the number of Person-years lost from incidents:187Annual revenue generated X Person-years lost:$165,207,830Percent of total revenue:10%
Which number creates a greater sense of urgency? Is it the number of Incidents per year, 14240, or $165,207,830? All Incidents cost the company money. Yes, the IT department must work together to reduce the resolution time. But the real effort should be to produce high-quality Incidents so that Problem Management can reduce recurring Incidents first, and to provide feedback to the Continuous Improvement and Service Design Practices for a zero-defect goal.
Incident Management + Problem Management BHAG (Big Hairy Audacious Goals) example:
Reduce recurring incidents by 10% per quarter for each IT Department.
Integrating all IT under Continuous Improvement
Metrics are essential for every Practice and every person. As Ken Blanchard repeatedly said, "Feedback is the breakfast of champions."
In the next section, Key Performance Metrics (KPIs) represent the traditional ITIL metrics. However, as we have seen, nothing in ITIL stands alone. Everything relates to everything else. KPIs are discrete metrics that are the result of many Practices and many relationships. To do ITIL right, we should take a holistic view of the organization. A holistic view means that, as you purposely change one thing, something else will also change.
Your SLAs are agreements between the business and IT. For example:
-
The company (i.e. users) agrees to use only the Service Desk Practice (Single Point of Contact, SPOC) to communicate an Incident.
Metric 1: Measure those users that don't follow this agreement so you can influence it.
-
The Service Desk creates the Incident. It attempts to resolve it at the Service Desk because:
- It increases customer satisfaction, and
- It is significantly less expensive to resolve at Level 1 than 2 or 3.
Since IT wants to reduce costs and increase customer satisfaction, we create OLAs between all IT departments. -
The Service Desk receives Incident training from Levels 2 and 3.
Metric 2: Measure the training hours.
-
The Service Desk receives diagnostic tools from Levels 2 and 3.
Metric 3: Measure the tools.
-
The Service Desk receives knowledge articles on how to diagnose Incidents, resolve them at level 1, and properly document the Incident.
Metric 4: Measure knowledge articles.
-
Levels 2 and 3 create Frequently Asked Questions (FAQs) for the Service Desk portal for the most common Incidents.
Metric 5: Measure how many avoided Incident escalations through user self-help.
-
Levels 2 and 3 ticket feedback to the Service Desk. For this to work, create a "Please Review" field. As the Level 2 or 3 technician reviews the escalated ticket, they enter feedback in a diary field. The Service Desk runs daily reports on "please review" Incidents and learns through their Continuous Improvement program.
Metric 6: Measure the number of "please review" Incidents. The goal is for the numbers to decline.
Summary:
- Metric 1: Number of users not following SPOC. (Goal: Declining trend)
- Metric 2: OLAs with all Incident escalation teams to improve communications and efficiency. (Goal: Increasing trend)
- Metric 3: Diagnostic tools for Levels 2 and 3 support. (Goal: Increasing trend)
- Metric 4: Knowledge articles from Levels 2 and 3. (Goal: Increasing trend)
- Metric 5: FAQs for user self-help. (Goal: Increasing trend)
- Metric 6: Just-in-time Incident-record feedback. (Goal: Decreasing trend)
CSF and KPI for Incident Management21
Critical Success Factor (CSF): A necessary precondition for achieving intended results.
Key Performance Indicators (KPI): An important metric to evaluate the success of meeting an objective.
-
CSF: Ensure that Incident Management uses standardized methods and procedures for efficient and prompt response, analysis, documentation, and reporting of Incidents to maintain business confidence in IT capabilities.
- KPI: Number and percentage of Incidents incorrectly assigned.
- KPI: Number and percentage of Incidents incorrectly categorized.
- KPI: Number and percentage of Incidents related to changes and releases.
-
CSF: Maintain quality of IT services.
- KPI: Total number of Incidents (as a control measure).
- KPI: Size of current Incident backlog for each IT service.
-
CSF: Resolve Incidents as quickly as possible, minimizing impacts to the business.
- KPI: Mean elapsed time to achieve Incident resolution by Impact Code.
- KPI: Percentage of Incidents closed by the Service Desk.
-
CSF: Align Incident Management activities and priorities with the business.
- KPI: Number and percentage of Incidents handled within an agreed response time.
- KPI: Average cost per Incident.
Incident Management best practices summary
We have explored what ITIL has to say about Incident Management. More than anything, the Incident Management Practice cannot succeed in isolation. Under the umbrella of Continuous Improvement, excellence is an IT initiative, not a practice or an individual IT department. It must be a focal point at the highest level of IT. As we have seen, Incidents cost the business lots of money in lost productivity.
Reducing the cost to the business is not an investment in tools and technology. It is a single, unrelenting elimination of the root cause of Incidents. And you cannot do that without 100% accurate Incident record data. That should be the goal of everyone that handles an Incident. If IT can do that, then all the other 33 ITIL Practices can use the data to improve.
Footnotes:
- ITIL® Foundation ITIL 4 Edition, AXELOS Limited 2019 p. 121
- Ibid, ITIL 4, p. 121
- Ibid, ITIL 4, p. 149
- Ibid, ITIL 4, p. 32
- Ibid, ITIL 4, p. 33
- ITIL 3, Service Operation, TSO, 2011, p. 76
- Ibid, ITIL 3, p. 76
- Ibid, ITIL 3, pp., 80-81
- Ibid, ITIL3, p. 104
- Ibid, ITIL 3, p. 79
- Ibid, ITIL 3, p. 80
- Ibid, ITIL 3, p. 80
- Ibid, ITIL 3, p. 80
- Ibid, ITIL 3, p. 80
- Ibid, ITIL 3, p. 77
- Ibid, ITIL 3, pp 82-83
- Ibid, ITIL 3, p. 74
- Ibid, ITIL 3, p. 74
- Ibid, ITIL 3, pp. 203-204
- Ibid, ITIL 3, p. 204
- Ibid, ITIL 3, pp. 85-86

About the Author
Bart Barthold
Bart Barthold is an independent senior ITIL instructor with years of experience in combining ITIL knowledge with practical expertise in running a world-class support organization. He has earned the certificate for the highest level of ITIL training - IT Service Manager, holds an MBA, and he has taught various ITIL certifications and hundreds of students since 2004.
Bart is known for his outstanding performance in IT service management and is a recipient of the Help Desk Institute's prestigious Team Excellence Award in 1998. He also finished second in 1997, making him one of the most decorated IT service managers in the industry.