SLA Breach Root Cause Analysis: How to Find What's Causing Your Help Desk Ticketing Breaches
 By Ron Avignone
By Ron Avignone
Your SLA compliance report is honest about what happened. It shows that 20% of tickets missed their target last month. What it does not show is whether those tickets fell behind during initial assessment, sat unclaimed in an escalation queue, or lost time because the SLA clock was counting down on a ticket already in pending. Without that breakdown, any fix you apply is a guess.
Our guide below walks through a five-step investigation process for isolating exactly which part of your help desk workflow is responsible. It covers how to pull and read breach data, break it down stage by stage, trace each finding to a root cause, and build a review plan that catches problems before they compound.

Key Takeaways
- Most SLA breaches trace back to one of three root categories: people gaps, process design flaws, or ITSM configuration errors. Staffing headcount is rarely the only factor.
- The ticket lifecycle stage with the widest gap between expected and actual time is where the root cause sits. Escalation handoffs and pending hold times are the two most consistent suspect areas.
- A missing Operational Level Agreement (OLA) or a misconfigured SLA timer can produce a pattern of breaches that looks like a team performance problem in standard breach reports.
- A monthly breach review covering team patterns, OLA performance, and ITSM configuration changes is the minimum cadence for teams targeting 90%+ SLA compliance.
What Is SLA Breach Root Cause Analysis?
SLA breach root cause analysis is the process of identifying the specific stage, team, or configuration in your help desk workflow that caused a ticket to miss its Service Level Agreement (SLA) target.
Most help desk teams have some form of post-breach review. A manager looks at the breached ticket, asks what happened, and makes a note. That is useful for handling individual incidents, but it is much less useful for fixing the underlying pattern. Systematic root cause analysis applies a structured investigation across all breached tickets over a period, looking for the shared cause or causes that keep coming up.
Standard RCA methods such as the Five Whys (asking "Why" repeatedly until you reach the root cause) or a Fishbone Diagram (mapping categories of cause against an effect) can be useful for deep-diving into a single critical breach. However, the process we map out below takes a broader approach. It starts with data across all breaches to identify which lifecycle stage and root cause category to focus on, then applies those deeper methods where they are most useful.
Why "We Keep Missing SLAs" Is Not a Root Cause
In SLA management, the standard response is to treat a rising breach rate as the problem to solve. It is a symptom, not a cause. Telling teams to respond faster or to be more attentive does not address why specific stages in the ticket lifecycle are slow.
Root cause analysis gets specific, answering if the breach was caused by a long initial-assessment queue, a slow handoff between teams, or a misconfigured SLA timer. Each of those is a different problem with a different fix. Knowing which one applies is the whole point of the investigation.
The Three Categories to Investigate
Most SLA breaches trace back to one of three types of causes:
-
People causes:
- Staffing levels
- Skill gaps
- Workload distribution
- Agent awareness of approaching deadlines
-
Process causes:
- Escalation paths
- Handoff procedures
- Ticket prioritization rules
- Operational Level Agreement (OLA) commitments between teams
-
Technology causes:
- SLA timer configuration
- Automation rules
- Routing logic
- Integrations between your ITSM tool and other systems
These categories help frame your investigation. When you identify a lifecycle stage that is consuming more time than expected, the framework helps you ask the right diagnostic question about why.
Step 1: Pull Your SLA Breach Report and Look for Patterns
A breach report filtered by team, ticket type, and time period will reveal patterns that individual ticket reviews cannot, and most IT Service Management (ITSM) platforms support all three of these filters natively.
Before investigating individual tickets, let the aggregate data narrow your search area. At this stage, focus on clustering rather than individual ticket detail.
Starting with Volume and Trend Data
Pull a breach report for the last three months and look at the trend line. Is the rate stable, increasing, or spiking at certain points? A stable 8% breach rate points to a structural issue in the process. A sudden jump from 4% to 12% usually points to a specific trigger, such as a staffing change, a system migration, or an unusual surge in ticket volume.
Month-over-month comparison tells you whether you are dealing with a chronic process problem or an acute one. Chronic problems require process fixes. Acute problems often trace back to a specific change in resources or demand.
A 2024 Broadcom survey of more than 500 IT professionals found that 61% of organizations experience SLA breaches monthly or more frequently. That frequency points to structural causes rather than isolated incidents. If a team is breaching at that cadence, the investigation should focus on recurring process or configuration gaps, not on individual tickets.
Team and Ticket-Type Patterns
Filter the breach report by team and by ticket category. If 70% of breaches belong to one team or one ticket type, your investigation scope narrows significantly.
A high concentration in a specific ticket category, such as hardware requests or access provisioning, often points to a bottleneck specific to that workflow, such as a vendor dependency, an approval step, or a missing automation. A high concentration in a specific team points toward capacity or skill issues within that team.
Time-of-Day and Day-of-Week Patterns
SLA breaches that cluster on Monday mornings, end-of-month periods, or after-hours shifts point directly to staffing gaps rather than process design. If most breaches happen on tickets opened on Fridays, it suggests that those tickets run out of calendar time before agents return to them the following week.
One useful addition to your ITSM setup is a "delay reason" field on tickets. When agents document why a ticket was delayed before closing it, breach data becomes much more diagnostic. The field takes seconds to complete and turns anecdotal incident reports into searchable trend data over time.
Step 2: Break Down the Ticket Lifecycle Stage by Stage
Your SLA clock runs from ticket creation to resolution. But the time inside that window is not one uniform block. It is spent in distinct stages, each with its own typical duration and its own failure point. Finding which stage is consuming more than its share is the key diagnostic task.
The Stages Where SLA Time Is Spent
The stages below cover a typical ticket lifecycle from creation to resolution. Each row shows what a significant delay at that stage usually indicates.
Stage |
What It Measures |
What a Long Time Here Suggests |
Assessment and intake |
Time from ticket creation to first assignment |
Unmonitored queues, no auto-routing, too few available agents at intake |
First response |
Time from assignment to first agent reply to the requester |
Overloaded agent queues, no visibility into pending tickets, alert fatigue |
Active working |
Time the agent is actively engaged on the ticket |
Complex issue type, missing knowledge resources, lack of necessary access or tools |
Pending / waiting |
Time in on-hold or waiting-for-customer status |
SLA timer pause rules being used to mask process delays (watermelon effect), or slow customer response |
Escalation and handoff |
Time from escalation trigger to the next team's first activity |
No escalation path defined, wrong team assignment, receiving team at capacity or unalerted |
Resolution and close |
Time from solution identified to ticket closed |
Approval bottlenecks, required sign-off steps, or closure steps that agents defer |
Most ITSM tools record a timestamp every time a ticket changes status, owner, or priority. That audit trail is your raw data for this analysis. You are looking for the stage with the widest gap between its expected time budget and its actual average.
How to Extract Stage-Level Timing from Your ITSM Tool
Look for the ticket event log or audit history in your ITSM platform. Each status change, assignment change, and escalation event carries a timestamp and a user or system action. You can calculate time spent in each stage by finding the difference between consecutive timestamps for the same ticket.
Many platforms offer built-in reports for First Response Time (FRT), time to resolve, and time in queue by team. If those reports are available, start there. For finer granularity, such as time per escalation hop across multiple teams, you may need to export the event log and process it in a spreadsheet.
Process mining tools, which analyze event log data to map actual process flows across large ticket sets, can automate this analysis at scale. This is not necessary for an initial investigation, but it becomes practical once systematic breach audits become part of your regular process.
Where Time Typically Disappears
Escalation handoffs can be where time disappears consistently. A ticket escalated from Tier 1 to Tier 2 may sit in the new queue for hours with no activity, because the receiving team has no alert, no SLA visibility, and no formal time commitment for responding to escalated work.
Here is an example scenario: A technology services team providing IT support to enterprise clients, after pulling their event log data, found that more than half of their Tier 2 escalated tickets spent over four hours in the escalation queue before any activity occurred. The cause then was not capacity. After investigation, they discovered that escalation notifications were routing to a shared inbox that no one was actively monitoring. The breach was a configuration problem, not a staffing one.
The pending and waiting stage can be another consistent time sink, and the harder one to diagnose because it hides behind a legitimate status. An agent moves a ticket to "pending" while waiting on a vendor response and forgets to reopen it. Or the ticket is set to pending because the agent cannot proceed, which is a process problem, not a customer-wait problem. Reviewing what share of pending time is actually customer-driven versus process-driven is an important part of this step.
Event log analysis across multi-team workflows also reveals a pattern that is easy to misattribute. The team that holds a ticket longest before escalating is often not the team blamed for the breach. The receiving team picks up a ticket that has already consumed most of its SLA window through upstream delays, then breaches during active work or resolution. Pulling event log data by each team transfer point, rather than by ticket owner at the time of breach, is how you identify where the time actually went.
Step 3: Map Each Stage to a Root Cause
Once you know which stage is slow, the People/Process/Technology framework helps you determine why. Match the slow stage to its root cause category in the table, check the diagnostic question listed, and work through the common causes for that category.
Category |
Stage Most Commonly Affected |
Diagnostic Question |
Common Cause |
People |
Assessment, first response |
Are there enough agents available during the hours when this stage is delayed? |
Understaffing, alert fatigue, or low-priority tickets getting missed |
People |
Active working |
Are tickets assigned to agents who lack the skills or access to resolve them? |
Incorrect routing, inadequate training, or no knowledge base access |
Process |
Escalation and handoff |
Is there a defined escalation path, and does the receiving team have a committed response time? |
Missing OLA, unclear escalation trigger, or handoff with no named owner |
Process |
Pending / waiting |
Are tickets being set to pending for reasons beyond waiting for the customer? |
SLA clock pause abuse, no required reason field, or agent unable to proceed |
Process |
Any stage |
Are SLA targets based on actual team capacity, or were they set arbitrarily? |
Unrealistic SLA windows that no amount of efficiency improvement will meet |
Technology |
Any stage |
Is the SLA timer starting and stopping at the correct events for each priority level? |
Misconfigured SLA rules, wrong clock start point, or incorrect priority-to-SLA mapping |
Technology |
Assignment and routing |
Are tickets landing in the correct queue automatically? |
Stale routing rules, deactivated accounts still listed as owners, or disconnected integrations |
Aim for one or two specific hypotheses before moving to fixes. For example: "Our escalation handoff time is long because Tier 2 has no OLA and no alert," or "Our first response time spikes on Mondays because weekend tickets are not initially handled until Monday morning." A specific hypothesis leads to a targeted fix.
Step 4: Audit Your SLA Configuration for Hidden Errors
Not all SLA breaches are caused by how your team performs. Some are caused by how your ITSM tool is configured. An SLA configuration audit is a step many help desk managers skip, partly because it requires administrator access, and partly because configuration errors are not directly visible in breach reports, showing up instead as patterns that look like process or staffing problems.
Pause Rules and the Watermelon Effect
The Watermelon Effect describes a situation where your SLA metrics look green (compliant) on the outside while the actual customer experience is still poor (red inside). It happens when tickets are moved to an on-hold or pending status to pause the SLA clock, even though the customer is still waiting for a resolution and the underlying issue is unsolved.
To check for this, pull all tickets that spent time in a paused status and review the documented reason. If your ITSM tool does not capture a reason for status changes, that is itself a gap. Legitimate pauses happen when the customer has not responded to a request for information. Pauses that happen because an agent cannot proceed, because a vendor has not responded, or because a ticket is stalled in an internal approval step are process problems being obscured by a timer stop.
Fix this by establishing specific, documented rules for when the SLA clock should pause. Require agents to select from a predefined reason list when setting a ticket to pending. Review pause-reason data monthly and flag tickets where pause time exceeded a threshold that is not explained by documented customer delays.
SLA Clock Start and Stop Settings
Check when your SLA clock starts. Does it begin when the ticket is created, when it is first assigned, or when it is first viewed by an agent? A misaligned start point can make tickets appear compliant in reporting while actual response times are longer than the agreed target.
Check the SLA target assigned to each priority level. A ticket that is miscategorized as Priority 3 when it should be Priority 1 gets a longer SLA window and may technically comply while the customer experiences a response time that does not match the agreement.
Check whether the SLA countdown is visible to agents in their default ticket view. If agents can only see how much time remains by navigating to a separate report, they are relying entirely on automated alerts to stay aware of approaching deadlines. If those alerts are misconfigured or arrive too late, the first indication of a problem may be a breach notification rather than a warning.
Escalation Routing Gaps
Review the escalation rules in your ITSM tool and trace them against the lifecycle data from Step 2. Do tickets that should auto-escalate after a set time actually do so reliably? Does the escalation route to the correct team or individual?
A common gap is escalation rules that were configured correctly at implementation but were never updated after team restructuring or staff changes. A rule pointing to a no-longer-existing team queue or a deactivated user account can leave escalated tickets routing to no one while the SLA clock continues.
If your team does not have a documented incident escalation policy that specifies auto-escalation triggers, routing targets, and time windows, writing one is the most direct fix for persistent handoff delays.
Step 5: Use Operational Level Agreements to Assign Stage Ownership
Operational Level Agreements (OLAs) are internal commitments between teams that define how long each handoff stage in a multi-team service chain is expected to take. Where an SLA is a customer-facing commitment, an OLA is the internal structure that makes that commitment deliverable.
What an OLA Is and Why It Matters
An Operational Level Agreement (OLA) is a documented agreement between two internal teams that specifies each party's response time, responsibilities, and escalation triggers for a given service workflow.
When escalation handoff time is a confirmed root cause of your SLA breaches, the absence of an OLA is almost always part of the explanation. Without an OLA, the receiving team has no formal commitment and no accountability mechanism for escalated work. They may have other priorities, or there is no alert, no time target, and no measurement.
Mapping OLAs to Your Breach Data
Start with the handoff stages that showed the longest delays in Step 2. For each one, ask whether there is a documented OLA between the sending and receiving team. If there is not, your next action is to define one.
For example, an OLA for a Tier 1 to Tier 2 escalation might define that Tier 2 acknowledges the ticket within 30 minutes during business hours, begins active work within two hours, and escalates to Tier 3 or a vendor within four hours if the issue is not resolved. Each of those time windows is measurable and reportable in your ITSM tool.
Building OLAs from real breach data has a practical advantage over designing them in theory, with the time targets being grounded in actual performance. If your stage-level data shows that Tier 2 currently takes an average of 45 minutes to acknowledge an escalated ticket, setting the OLA target at 30 minutes is an achievable improvement goal with a clear measurement baseline.
OLAs also apply to external dependencies. In ITIL terminology, the equivalent of an OLA for a third-party supplier is an Underpinning Contract (UC): a formal agreement that defines the vendor's response time, responsibilities, and escalation contacts. When a vendor is in the resolution path and there is no UC or equivalent agreement, their delays are merged into your team's pending time and are invisible in standard breach reporting.
How to Build a Repeatable SLA Breach Review Process
Single-incident root cause analysis is useful for critical tickets. The systemic version, run consistently across all breaches over a defined period, is what produces lasting improvement. A repeatable review process turns breach analysis from a one-time audit into an ongoing quality control function.
Breach Review Cadence
A monthly SLA breach review should cover:
- Breach report data filtered by team and ticket type
- Stage-level timing trends since the previous review
- OLA performance data by team
- Configuration changes made to the ITSM tool since the last session
The meeting should include the help desk manager, team leads, and whoever manages the ITSM tool configuration.
Each review should produce a short list of action items. Typical items include any of these:
- A new OLA to define
- An escalation rule to update
- A staffing pattern to adjust
- A training gap to address
Without documented actions tied to each review, breach analysis becomes informational rather than corrective.
During periods of elevated breach rates, move to weekly reviews. A one-month gap between sessions is too long when the rate is rising quickly.
Proactive Alerts Before a Breach Occurs
The most direct way to prevent breaches is to alert agents and managers before the SLA window closes. Most ITSM platforms support threshold-based alerts at 75% and 90% of SLA time remaining.
The 75% alert gives an agent time to act. The 90% alert escalates to a manager or senior agent. The combination converts SLA management from reactive (we breached, now we investigate) to preventive (the clock is running low, act now).
More advanced ITSM implementations also use anomaly detection to flag unusual patterns in ticket volume or resolution time before they become systemic problems, giving managers early warning of a capacity or process issue rather than discovering it from a spike in the breach rate.
Common SLA Breach Root Causes by Category
The following reference organizes the most frequently identified SLA breach root causes by category. Use it as a starting checklist once your stage-level analysis has narrowed the search to a specific lifecycle phase:
-
People Causes
- Understaffing during peak hours, specific shifts, or seasonal volume spikes
- Alert fatigue from high ticket volume and too many concurrent notifications competing for agent attention
- Skill mismatch from incorrect routing, specifically a complex or specialized ticket assigned to an agent who lacks the training or access to resolve it
- Lack of visibility into approaching SLA deadlines, particularly when agents are managing large queues without a real-time SLA status view
- Incorrect priority assignment at intake, either by the submitting user or by auto-routing that misclassifies ticket type
-
Process Causes
- Missing or undocumented escalation path, meaning agents do not know who to escalate to or when, so escalated tickets stall
- Missing OLAs for internal team handoffs, leaving each team without a formal time commitment for escalated work
- Unrealistic SLA targets set without reference to actual team capacity or ticket volume patterns
- On-hold or pending status used to pause the SLA clock on tickets that are not genuinely waiting for customer input
- No mandatory reason field for ticket status changes, which prevents abuse from being identified in reporting
- Ticket aging not monitored between status changes, so a ticket can sit in a queue for hours with no owner checking progress
-
Technology Causes
- SLA clock starting at first assignment or first view rather than ticket creation, artificially widening the compliance window
- Misconfigured pause rules that stop the clock during internal delays rather than only genuine customer-wait periods
- Routing rules pointing to outdated team queues or deactivated accounts, causing auto-escalated tickets to route to no one
- Disconnected systems, specifically when the monitoring platform, Configuration Management Database (CMDB), and ITSM platform do not share data, which slows ticket creation or prevents automated escalation triggers
- Missing threshold-based SLA alerts, leaving agents unaware that a deadline is approaching until it has already passed
- External dependency tracking gaps, where third-party vendors or upstream teams are part of the resolution path but their response time is not tracked against any OLA or vendor agreement, causing their delays to appear as undifferentiated "pending" time in your data
Frequently Asked Questions About SLA Breach Root Cause Analysis
-
What is the most common cause of SLA breaches?
The most common cause of SLA breaches is a combination of process gaps and insufficient visibility into approaching deadlines, not a single staffing shortage.
In most help desk environments, the root cause is one or more of the following:
- A handoff stage with no defined time target or responsible owner
- SLA alerts that fire too late or reach the wrong person
- Tickets sitting in a pending or on-hold status that is not actively monitored
Understaffing contributes to breaches but is rarely the only factor. Teams that improve their escalation process and alert configuration often see compliance rates improve without adding headcount.
-
What is an OLA and how does it prevent SLA breaches?
An Operational Level Agreement (OLA) is an internal agreement between two support teams that defines each team's response time and responsibilities within a shared service workflow.
OLAs prevent breaches by assigning a measurable time target and a named owner to each handoff stage in the service chain. When a Tier 1 team escalates a ticket, the Tier 2 OLA defines how quickly that team must acknowledge and begin work. Without an OLA, the Tier 2 team has no formal commitment, and escalation delays go untracked until they accumulate into an SLA breach.
OLAs are most valuable when built from real breach data. If your stage-level analysis shows that escalation acknowledgment currently averages 45 minutes, an OLA target of 30 minutes is an improvement goal with a measurable baseline.
-
What is the Watermelon Effect in SLA management?
The Watermelon Effect is when SLA metrics appear green (compliant) while the actual customer experience is still poor, green on the outside and red on the inside.
It typically happens when tickets are moved to an on-hold or pending status to pause the SLA clock, even though the underlying issue is unresolved and the customer is still waiting. The timer stops, the compliance metric improves, and the real delay goes undocumented.
The fix is to establish documented rules for legitimate clock pauses, such as when the customer has not responded to a request for information, and to require agents to select a reason when setting a ticket to pending. Regular audits of pause-reason data will reveal abuse patterns over time.
-
How do I calculate my SLA compliance rate?
SLA compliance rate is calculated by dividing the number of tickets resolved within their SLA target by the total number of tickets reviewed, then multiplying by 100.
Formula: SLA compliance rate % = (Tickets resolved within SLA target / Total tickets) × 100
A compliance rate of 90 to 95% is the widely cited target across most IT service management environments. The right target for your team depends on ticket volume, team size, and the priority mix of your requests. Teams handling a high share of critical incidents may aim higher, while teams with a broad mix of routine service requests often set tiered targets by priority level. SLA compliance rate is one of several key SLA metrics that help desk managers track alongside first response time and time to resolve.
-
How often should I review SLA breach data?
Monthly breach reviews are the standard minimum, with weekly reviews recommended during periods of elevated breach rates.
A monthly review looks at breach trends, team-level patterns, OLA performance, and any configuration changes since the previous session. That often is long enough to capture meaningful trends and short enough to act on emerging problems before they compound.
When breach rates climb sharply, a one-month gap is too long. Move to weekly reviews until the rate stabilizes, then return to monthly once the corrective changes are in place and producing results.
Related Giva Resource
- Implementing Service Level Agreements: IT Service Desk Guide
- SLA Formula: How to Calculate and Improve Service Level Agreement Scores
- What is SLM? ITIL Service Level Management: Meaning, Purpose and Process
From Pattern to Process: Making SLA Breach Analysis a Routine Practice
The five-step methodology in this guide is designed to be used repeatedly, not just once. A single investigation tells you what was wrong last month. Repeated investigations, run consistently against the same data points, tell you whether your fixes are working and where new problems are developing.
Teams that maintain strong SLA compliance rates are not usually the ones with the most advanced tools, and the advantage is cumulative. Each round of analysis raises the baseline, and problems that would otherwise stay invisible get caught earlier. Strong ticket management foundations, including complete audit trails, consistent priority assignment, and structured status workflows, are what make this kind of analysis possible in the first place.
If your investigation turns up a problem that goes beyond a configuration fix or a process adjustment, such as a structural capacity gap or a need for a new escalation tier, that finding is also valuable. It gives you the evidence to make a case for the resources or changes your team needs, rather than asking leadership to act on a general sense that something is wrong.
How Giva Supports SLA Breach Investigation and Prevention
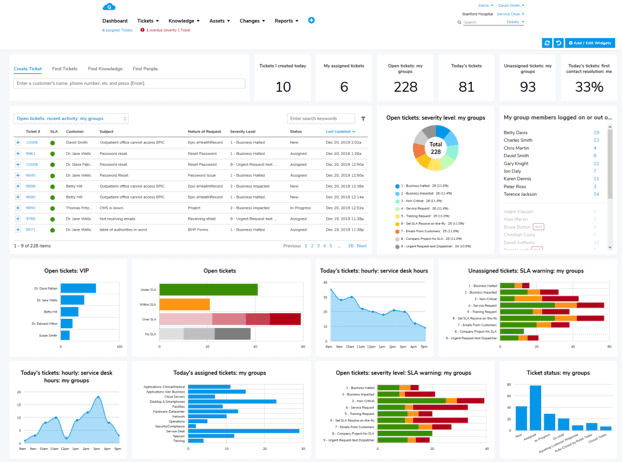
Giva's Help Desk and ITSM Software is built with streamlined operational visibility in mind. You can configure Service Level Agreements for response and resolution times, configure SLA breach notifications for each ticket service department and priority level, and track SLA compliance and breach statistics and trends.
Other key Giva features include:
Whether you are investigating a pattern of breaches for the first time or building out a formal SLA review process, having the right tools makes the difference between anecdotal fixes and measurable improvement.
Ready to learn more? Get a demo to see Giva's solutions in action, or start your own free, 30-day trial today!



Categories: Help Desk